Advancing Scientific Rigor: Strategies to Minimize False Positives in Retrospective Premenstrual Symptom Research
This article addresses the critical methodological challenge of false-positive retrospective reports in premenstrual disorder research, a significant concern for etiologic studies and drug development.
Advancing Scientific Rigor: Strategies to Minimize False Positives in Retrospective Premenstrual Symptom Research
Abstract
This article addresses the critical methodological challenge of false-positive retrospective reports in premenstrual disorder research, a significant concern for etiologic studies and drug development. It explores the foundational limitations of retrospective recall, which is biased toward false positives and confounded by participant beliefs and non-cyclical symptoms. The content provides a comprehensive framework for implementing gold-standard prospective daily rating methodologies as mandated by DSM-5 diagnostic criteria. It further offers troubleshooting strategies for common operational hurdles and outlines validation techniques, including cross-validation with other data sources and comparator studies, to ensure data integrity and reliability for regulatory-grade evidence.
The Problem of False Positives: Understanding the Limits of Retrospective Recall in Premenstrual Research
Frequently Asked Questions (FAQs)
FAQ 1: Why is retrospective assessment particularly problematic for diagnosing cyclical conditions like PMDD?
Retrospective assessments, where patients recall their symptoms over a previous period, lack validity for cyclical conditions due to several cognitive and methodological pitfalls:
- Recall Bias and Cognitive Heuristics: Patients' memories of symptoms are susceptible to distortion. They may disproportionately recall the most recent or severe episodes, a cognitive shortcut that fails to capture the precise pattern of a cyclical condition [1].
- Inability to Establish Temporal Pattern: The core feature of a condition like Premenstrual Dysphoric Disorder (PMDD) is the specific on-off pattern of symptoms in relation to the menstrual cycle. Retrospective recall cannot accurately establish this precise timing, leading to confusion with other disorders that have premenstrual exacerbation [2].
- Artificially Inflated Prevalence: Studies consistently show that reliance on retrospective, or "provisional," diagnosis produces significantly higher prevalence rates. A 2024 meta-analysis found the pooled prevalence for PMDD was 7.7% with provisional diagnosis but only 3.2% when confirmed by prospective daily ratings [3].
FAQ 2: What is the gold-standard methodology for confirming a cyclical condition in clinical research?
The gold standard for diagnosing cyclical conditions like PMDD involves prospective daily symptom monitoring over at least two menstrual cycles [3] [2]. This method requires patients to rate symptoms each day, which allows researchers to conclusively link symptom onset and offset to specific menstrual phases (luteal vs. follicular) and confirm the cyclical pattern.
FAQ 3: Our team is designing a clinical trial for a PMDD treatment. What are the key methodological considerations for patient stratification?
When stratifying patients in a PMDD trial, you must:
- Use Prospective Confirmation: Do not rely on patient self-referral or retrospective questionnaires alone. Implement a screening phase with prospective daily symptom tracking [3] [4].
- Apply Standardized Diagnostic Algorithms: Use validated scoring systems, such as the Carolina Premenstrual Assessment Scoring System (C-PASS), to analyze daily diaries. These algorithms objectively determine if a patient meets diagnostic thresholds based on the percentage increase in premenstrual symptom scores and their absolute severity [4].
- Measure Functional Impairment: Assess the impact of symptoms on work, social, and relational functioning, as this is a key validator for clinical significance [4].
Troubleshooting Common Experimental Issues
Problem: High screen-failure rate in our PMDD study, with many retrospective reports not confirmed by prospective diaries.
- Solution: This is an expected outcome that validates your rigorous methodology. The discrepancy highlights the inaccuracy of retrospective recall. To improve efficiency, consider using validated tools that focus on a core set of discriminatory symptoms during the screening phase [5].
Problem: Participant burden and missing data from daily diary protocols.
- Solution:
- Utilize digital platforms or mobile apps for daily reporting to simplify data entry and send reminders.
- Research indicates that the burden of daily diaries can be reduced. One study found that tracking just six core symptoms (e.g., anxiety/tension, mood swings, decreased interest in activities) was as effective at discriminating PMS as tracking 17 symptoms [5].
Problem: How do we handle data from participants who experience a major stressful event during the monitoring period?
- Solution: Pre-define a protocol for such events. In one cited study, days on which participants reported a significant external stressor unrelated to their symptoms (e.g., "my wallet was stolen") were coded as missing to prevent confounding the analysis of symptom cyclicity [4]. This should be clearly documented in your statistical analysis plan.
Experimental Protocols & Data
Protocol: Prospective Daily Symptom Monitoring for PMDD
Objective: To confirm a PMDD diagnosis by prospectively tracking the cyclical nature of symptoms and functional impairment across two menstrual cycles.
Materials:
- Validated daily symptom report (e.g., Daily Record of Severity of Problems - DRSP [4] or Penn Daily Symptom Report - DSR [5])
- Method for daily data collection (paper forms mailed weekly [4] or digital application)
Procedure:
- Enrollment: Recruit participants who retrospectively report premenstrual emotional symptoms.
- Baseline Assessment: Conduct a structured clinical interview (e.g., SCID-I) to exclude current major psychiatric disorders [4].
- Daily Reporting Phase: Participants complete the daily symptom report for two full menstrual cycles. The DRSP, for example, includes all DSM-5 PMDD symptoms and items assessing relational, occupational, and recreational impairment [4].
- Data Analysis: Score cycles using a validated system like C-PASS [4]:
- For each symptom, calculate the percent premenstrual elevation:
(Average premenstrual week rating - Average postmenstrual week rating) / Total scale range * 100. - Apply diagnostic criteria: a symptom is clinically significant if it shows a ≥30% premenstrual elevation, absolute clearance post-menstrually (max score ≤3 "Mild"), and sufficient absolute premenstrual severity (max score ≥4 "Severe") [4].
- For each symptom, calculate the percent premenstrual elevation:
Quantitative Data on Diagnostic Validity
Table 1: Impact of Assessment Method on PMDD Prevalence [3]
| Assessment Method | Pooled Prevalence (95% CI) | Key Implication |
|---|---|---|
| Provisional Diagnosis (Retrospective recall) | 7.7% (5.3% - 11.0%) | Artificially inflates perceived disease burden |
| Confirmed Diagnosis (Prospective daily ratings) | 3.2% (1.7% - 5.9%) | Provides a more accurate prevalence estimate |
| Confirmed (Community-based samples only) | 1.6% (1.0% - 2.5%) | Highest diagnostic certainty |
Table 2: Core Symptoms for Discriminating PMS in Daily Diaries [5]
| Rank | Symptom Category | Function in Discriminating PMS |
|---|---|---|
| 1 | Anxiety/Tension | Affective core symptom |
| 2 | Mood Swings | Affective core symptom |
| 3 | Aches | Somatic symptom |
| 4 | Appetite/Food Cravings | Somatic/Behavioral symptom |
| 5 | Cramps | Somatic symptom |
| 6 | Decreased Interest in Activities | Psychological/Behavioral symptom |
Note: A model using these 6 core symptoms performed as well (AUC=0.84) as a model with all 17 symptoms, reducing patient and clinician burden [5].
Methodological Visualizations
Diagnostic Workflow for Cyclical Conditions
Retrospective vs. Momentary Assessment Validity
The Scientist's Toolkit: Key Research Reagents
Table 3: Essential Materials for PMDD Clinical Research
| Item | Function in Research | Example / Note |
|---|---|---|
| Structured Clinical Interview (SCID-I) | Rules out current major psychiatric disorders (e.g., mania, psychosis) to ensure a clean cohort [4]. | Standard in psychiatric research. |
| Prospective Daily Diary | The core tool for gold-standard diagnosis. Tracks symptom severity and timing daily [5] [4]. | Daily Record of Severity of Problems (DRSP); Penn Daily Symptom Report (DSR). |
| Diagnostic Scoring Algorithm | Objectively analyzes daily diary data to apply formal diagnostic criteria, removing subjectivity [4]. | Carolina Premenstrual Assessment Scoring System (C-PASS). |
| Functional Impairment Scale | Quantifies the real-world impact of symptoms (relational, occupational, recreational), validating clinical significance [4]. | Often embedded within diaries like the DRSP. |
Troubleshooting Guides
Problem: Inconsistent genetic associations or polygenic score performance between studies or populations.
| Suspected Cause | Diagnostic Check | Solution |
|---|---|---|
| Low Statistical Power & Winner's Curse [6] | Check sample size of index and replication studies. Observe if effect sizes are attenuated in larger samples. | Use shrinkage methods [6], increase sample size via collaborations, apply bias-correction techniques. |
| Population Stratification & Confounding [6] | Test for differences in allele frequencies and linkage disequilibrium (LD) patterns between populations. | Use genetic principal components as covariates, apply family-based study designs, utilize methods that account for population structure. |
| Genotyping/Imputation Errors [6] [7] | Check quality control metrics (e.g., call rate, MACH R2, INFO scores). Look for excess heterozygosity. | Apply stringent QC filters, use appropriate ancestry-matched reference panels for imputation, verify key findings with sequencing. |
| P-hacking & Flexible Analysis [8] | Determine if multiple statistical models or phenotype definitions were tested without correction. | Pre-register analysis plans, use hold-out samples for validation, correct for multiple testing (e.g., Bonferroni). |
Guide 2: Addressing False Positives in Premenstrual Disorder Research
Problem: Inflated prevalence rates and heterogeneous findings in studies of premenstrual disorders.
| Suspected Cause | Diagnostic Check | Solution |
|---|---|---|
| Retrospective Symptom Reporting [4] [3] [9] | Compare the number of participants meeting criteria via retrospective screening vs. prospective daily tracking. | Use prospective daily ratings for at least two symptomatic cycles (e.g., with the Daily Record of Severity of Problems - DRSP) [4] [9]. |
| Insufficient Cyclical Symptom Criteria [4] | Analyze if the required number of symptoms is the best predictor of functional impairment. | Consider that fewer than five symptoms may predict significant impairment; ensure diagnostic thresholds are empirically validated. |
| Inaccurate Symptom Tracking Tools [9] | Evaluate if the tracking app or diary captures the full range and severity of emotional, physical, and cognitive symptoms. | Use validated, standardized tools like the DRSP. Develop user-centered apps that are easy to use even during symptomatic phases. |
| Comorbid Conditions [10] | Assess for co-occurring ADHD, depression, or anxiety, which may confound symptom reporting. | Screen for and account for comorbidities in the analysis to isolate the unique effect of premenstrual symptoms. |
Frequently Asked Questions (FAQs)
Q1: What is the fundamental difference between a false positive and a false negative in research?
A1: A false positive (Type I error) occurs when researchers conclude an effect exists when it actually does not—a "false alarm" [11] [12]. A false negative (Type II error) occurs when they conclude no effect exists when one is actually present—a missed detection [11]. In genetics, a false positive might be declaring a genetic variant associated with a trait when it is not. In clinical research, it could be diagnosing someone with a condition they do not have.
Q2: How does prospective versus retrospective symptom reporting specifically reduce false positives in premenstrual dysphoric disorder (PMDD) research?
A2: Retrospective reports, where participants recall symptoms over a previous cycle, are highly susceptible to memory bias and general beliefs about premenstrual symptoms, leading to false positive diagnoses [9]. Prospective daily ratings require individuals to record symptoms each day, objectively confirming the cyclical pattern (luteal-phase onset and post-menstrual resolution) essential for a PMDD diagnosis [4] [3]. This method is the gold standard and significantly reduces misclassification.
Q3: What is the empirical evidence that retrospective reports inflate PMDD prevalence?
A3: Meta-analyses show a stark contrast. The pooled prevalence for provisional PMDD (often based on retrospective recall) is 7.7%. In contrast, the prevalence for confirmed PMDD (requiring prospective daily monitoring) in community-based samples is much lower, at 1.6% [3]. This dramatic difference highlights the extent of false positives introduced by non-prospective methods.
Q4: Beyond statistical power, what genetic factors can lead to false positive associations?
A4: Key factors include:
- Linkage Disequilibrium (LD): A true causal variant can show association, but non-causal variants in LD with it may also appear associated, creating false positive signals that differ across populations with distinct LD patterns [6].
- Population Stratification: Systematic differences in ancestry between cases and controls can create spurious associations if the ancestry is also correlated with the trait of interest [6].
- Genotyping Errors and Misalignment: Technical artifacts, especially in next-generation sequencing data, can create genotype false positives, particularly in certain genomic regions [7].
Q5: How can research policies help reduce the overall rate of false positives in science?
A5: Game-theoretic modeling suggests that policies targeting "mild" questionable research practices (QRPs), such as flexible data analysis and p-hacking, are most effective [8]. This includes enforcing transparency, pre-registration, and detailed reporting checklists. These measures reduce the incentives for milder QRPs, which in turn reduces the prevalence of more severe misconduct like data fabrication, thereby lowering the overall false positive rate [8].
Data Summaries
| Diagnostic Method | Definition | Pooled Prevalence (95% CI) |
|---|---|---|
| Provisional Diagnosis | Typically based on retrospective recall or cross-sectional assessment. | 7.7% (5.3% - 11.0%) |
| Confirmed Diagnosis | Requires prospective daily symptom monitoring over two cycles. | 3.2% (1.7% - 5.9%) |
| Confirmed (Community Samples Only) | Confirmed diagnosis applied specifically to community-based samples. | 1.6% (1.0% - 2.5%) |
Table 2: Key Reagent Solutions for Genetic and Clinical Research
| Reagent / Tool | Function in Research |
|---|---|
| Standardized Quality Control Cut-offs [6] | To exclude problematic SNPs and samples based on metrics like call rate, Hardy-Weinberg equilibrium p-value, and heterozygosity rate, reducing genotyping errors. |
| Ancestry-Matched Reference Panels [6] | To accurately impute missing genotypes, which is crucial for cross-population genetic analysis and reducing false positives due to poor imputation. |
| Daily Record of Severity of Problems (DRSP) [4] [9] | A validated daily diary for the prospective assessment of all DSM-5 PMDD symptoms and associated functional impairment. |
| Carolina Premenstrual Assessment Scoring System (C-PASS) [4] | A standardized, computerized system for diagnosing PMDD based on prospective DRSP ratings, providing both dimensional and diagnostic outputs. |
Experimental Protocols
Protocol 1: Prospective Daily Monitoring for PMDD Diagnosis
Objective: To confirm a PMDD diagnosis by prospectively tracking the cyclical nature of symptoms and functional impairment [4] [9].
Materials: Daily Record of Severity of Problems (DRSP) form (paper or digital).
Methodology:
- Participant Instruction: Participants are instructed to complete the DRSP every evening for a minimum of two consecutive menstrual cycles.
- Symptom Rating: The DRSP includes items for all 11 DSM-5 PMDD symptoms (e.g., mood swings, irritability, depressed mood) and three items assessing functional impairment (relational, occupational, recreational). Each item is rated on a scale of 1 (not present) to 6 (extreme).
- Cycle Phase Annotation: Participants mark the first day of their menstrual bleeding each cycle.
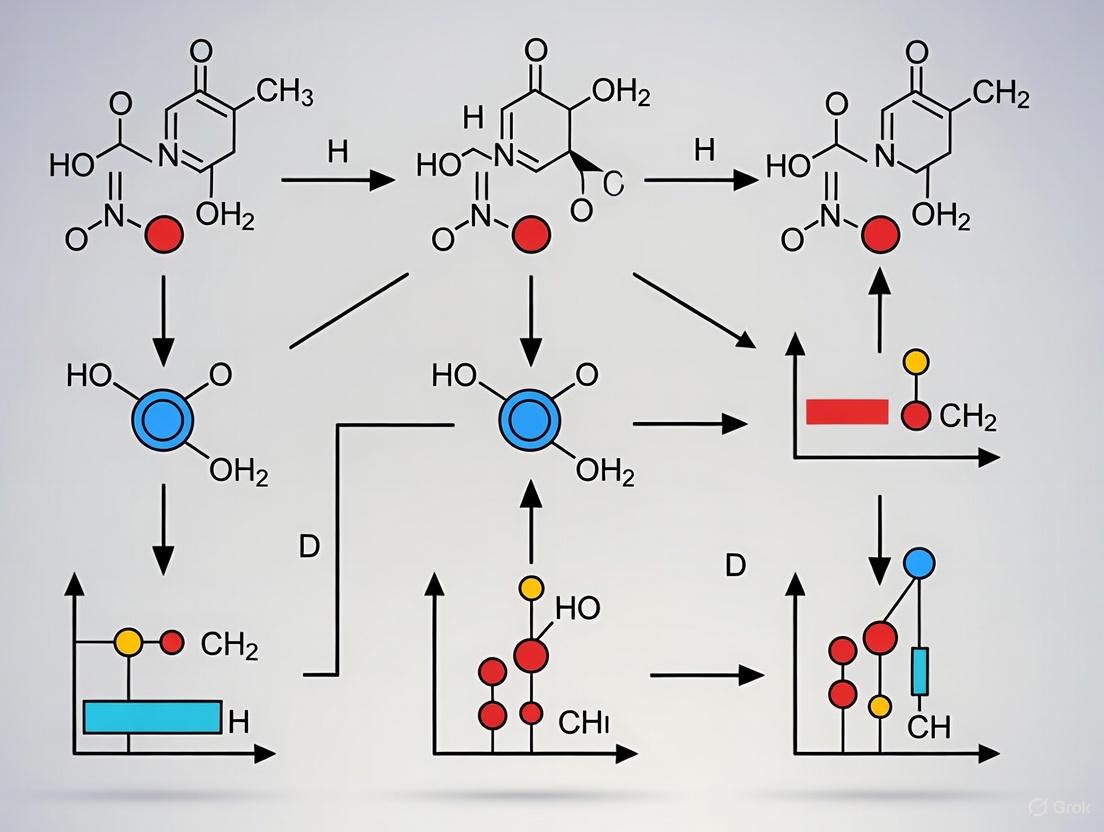
- Data Scoring (C-PASS): For each symptom in each cycle, the following is calculated [4]:
- Percent Premenstrual Elevation:
[(Average premenstrual week rating (days -7 to -1)) - (Average postmenstrual week rating (days 4 to 10))] / [Total scale range] * 100. - Diagnostic Decision: A symptom is considered clinically elevated if it meets three criteria:
- Relative Increase: Percent premenstrual elevation ≥ 30%.
- Absolute Clearance: Maximum postmenstrual week severity ≤ 3 ("Mild").
- Absolute Severity: Maximum premenstrual week severity ≥ 4 ("Moderate").
- Percent Premenstrual Elevation:
- Diagnosis: A PMDD diagnosis is confirmed if, for at least two cycles, the participant meets the DSM-5 threshold for the number of clinically elevated symptoms (including at least one core emotional symptom) [4].
Protocol 2: Quality Control and Imputation for Genome-Wide Association Studies (GWAS)
Objective: To minimize false positive genotype calls and ensure high-quality data for genetic association analysis [6] [7].
Materials: Raw genotype data from genotyping arrays, high-performance computing cluster, quality control software (e.g., PLINK, R), imputation server (e.g., Michigan Imputation Server).
Methodology:
- Sample-Level QC: Exclude individuals with:
- High genotype missingness (>2-5%).
- Sex discrepancies between genotypic and reported sex.
- Extreme heterozygosity rates (indicating contamination).
- Unmatched genetic ancestry (identified via principal component analysis).
- Variant-Level QC: Exclude single-nucleotide polymorphisms (SNPs) with:
- High missingness (>2-5%) across all samples.
- Significant deviation from Hardy-Weinberg Equilibrium (HWE p-value < 1x10⁻⁶) in controls.
- Very low minor allele frequency (MAF < 1%), as these are hard to genotype accurately.
- Imputation:
- Phasing: Estimate haplotypes from the genotyped data.
- Reference Panel: Use a large, ancestrally matched reference panel (e.g., 1000 Genomes Project, TOPMed).
- Imputation: Impute non-genotyped variants using the phased data and reference panel.
- Post-Imputation QC: Retain only well-imputed variants, typically with an imputation quality score (e.g., INFO score) > 0.8 [6] [7].
Visualizations
Diagnostic Pathway for PMDD
FAQ: Understanding and Mitigating Recall Problems in Genetic Studies
This section addresses frequently asked questions about the phenomenon of poor participant recall in genetic and longitudinal research.
Q1: What is the typical rate of participant recall in genetic studies, and what information is most commonly forgotten?
Research indicates that participant recall of genetic information is often imperfect and varies significantly depending on the type of information presented. The table below summarizes recall rates from empirical studies.
Table 1: Participant Recall Rates for Different Types of Genetic Information
| Information Type | Recall Rate | Time After Disclosure | Key Influencing Factors |
|---|---|---|---|
| Number of risk-increasing alleles (e.g., APOE ε4) | 83% | 6 weeks | Higher education, greater numeracy, stronger family history [13] |
| Specific genotype (e.g., ε3/ε4) | 74% | 6 weeks | Education, numeracy, family history, ethnicity [13] |
| Lifetime risk estimate (exact) | 51% | 6 weeks | Younger age [13] |
| Lifetime risk estimate (within 5 percentage points) | 84% | 6 weeks | Younger age [13] |
| Agreement to share genomic data | ~46% (54% could not correctly identify) | Variable (at follow-up) | Not significantly impacted by recall [14] |
| Having signed an informed consent form | ~73% (Over 25% did not remember) | Variable (at follow-up) | Acutely ill patients and longer time lapse showed lower recall [14] |
Q2: What are the primary factors that influence a participant's ability to recall complex genetic information?
Several demographic, cognitive, and emotional factors impact recall accuracy:
- Education and Numeracy: Participants with higher educational attainment and greater comfort with numerical concepts consistently show better recall of genotype-specific information and risk estimates [13].
- Age: Younger age has been independently associated with better recall of exact numerical risk estimates [13].
- Emotional State and Personal Relevance: The invitation to participate in a recall-by-genotype (RbG) study can cause temporary worry, leading participants to filter information through personal experiences like family history. However, studies show that participation itself causes a significant increase in worry for only a small fraction of participants [15].
- Information Overload: Complex concepts like genomic data sharing are difficult for participants to retain, especially when consent documents are long and detailed. Over 25% of participants in one study did not even remember signing a consent form [14].
Q3: What is the key ethical concern regarding participant understanding in informed consent?
A central ethical question is whether a participant's subjective understanding (feeling well-informed and comfortable with their decision) is sufficient for valid consent, even when objective understanding (measured recall and comprehension) is low. Research shows that participants who feel they understood the information are satisfied with their decision to participate, even if their objective recall is poor. This raises important questions about the types of information participants truly need for an ethical consent process [14].
Troubleshooting Guide: Improving Recall and Data Quality
This guide provides actionable protocols to address common problems related to participant recall and reporting inaccuracies.
Problem: High Rate of False-Positive or Inaccurate Retrospective Self-Reports
Root Cause: Retrospective data collection is highly susceptible to recall bias. Participants may underreport, overreport, or misremember past events, behaviors, or symptoms based on their current state, social desirability, or the mere passage of time [16].
Solution: Implement a Multi-Method Verification Strategy
- Prioritize Prospective Data Collection: Where feasible, design studies to collect data in real-time or at regular intervals during the event or period of interest (e.g., each trimester of pregnancy rather than post-partum). This is considered the gold standard for reducing recall bias [16].
- Use a Mixed-Methods Approach: Combine quantitative surveys with qualitative interviews. The interviews can help clarify survey responses and provide context that uncovers inaccuracies or nuances in recall [15].
- Triangulate with Objective Data: Corroborate self-reported data with medical records, administrative datasets, or biological verification where possible and ethically permissible [17] [16]. Be aware that the accuracy of these sources can also vary.
- Provide Structured Support During Disclosure:
- Use clear, plain language and visual aids like risk curves [13].
- Repeat key information in multiple formats (verbal, written) and over multiple contacts (e.g., a follow-up phone call) [13] [15].
- Have an expert (e.g., a genetic counselor) confirm understanding by asking participants to restate critical information in their own words and correct misunderstandings immediately [13].
Problem: Poor Participant Recall of Complex Genetic Concepts After Consent
Root Cause: Standard, lengthy informed consent documents can lead to information overload, making it difficult for participants to retain key details about the study, such as the scope of data sharing [14].
Solution: Adopt Enhanced Consent and Communication Practices
- Utilize Tiered Consent Models: Instead of an "all-or-nothing" approach, offer participants granular choices. For example, in genomic studies, a tiered consent document can allow participants to choose between public data release, restricted release to approved researchers, or no data sharing [14]. This engages participants in a more meaningful decision-making process.
- Implement Dynamic Consent: Use digital platforms that allow participants to revisit their consent choices, access educational materials, and receive updates over the course of a longitudinal study. This fosters ongoing engagement and understanding [15].
- Design a Robust Communication Strategy for Recall-by-Genotype (RbG):
- Be transparent about the disease being investigated in the recall, as this is important to participants [15].
- Carefully manage the disclosure of individual genetic carrier status, as this information can be a significant source of anxiety.
- Provide direct access to experts (doctors, genetic counselors) who can answer questions and alleviate concerns, which is a highly effective stress-relief mechanism for participants [15].
The following workflow outlines a comprehensive strategy to mitigate recall bias and improve data quality, from study design through to data collection and analysis.
Research Reagent Solutions: Essential Methodological Tools
This table details key methodological "reagents" — not wet-lab materials, but essential protocols and frameworks — for ensuring data quality in studies vulnerable to recall bias.
Table 2: Essential Methodological Tools for Recall-Sensitive Research
| Tool / Solution | Function | Application Context |
|---|---|---|
| Prospective Study Design | Collects data in real-time during the period of interest, minimizing the memory decay and reconstruction that plague retrospective reports [16]. | Gold standard for measuring symptoms, exposures, or experiences (e.g., prenatal stress, premenstrual symptoms). |
| Tiered Consent Model | Provides participants with granular data-sharing options (e.g., public, restricted, no release), enhancing engagement and understanding of complex data use [14]. | Genomic research and any study involving future data sharing or broad data use. |
| Dynamic Consent Platform | A digital interface allowing participants to review, update, and manage their consent choices over time, promoting ongoing engagement [15]. | Longitudinal studies, biobanks, and cohort studies where research goals may evolve. |
| Numeracy Assessment | An 8-item validated scale to assess a participant's comfort and ability with numerical concepts, allowing researchers to tailor risk communication [13]. | Studies disclosing numerical risk estimates (e.g., lifetime disease risk). |
| Mixed-Methods Approach | Combines quantitative data (e.g., surveys) with qualitative data (e.g., interviews) to provide context, clarify recall, and uncover the "why" behind the numbers [15]. | Useful for validating retrospective reports and understanding participant perspectives. |
| Global Trigger Tool (GTT) | A standardized two-stage chart review method to identify adverse events in medical records, serving as a validation benchmark for administrative data [17]. | Validating self-reported medical events or complications against clinical records. |
FAQs: Core Concepts and Troubleshooting
Q1: What is the fundamental methodological error in retrospective reporting of premenstrual symptoms?
Retrospective self-report assessment has poor validity and is biased toward false positives. It is significantly impacted by a participant's existing beliefs about premenstrual syndrome, rather than objectively capturing cyclical symptom patterns [18]. This is why modern diagnostic criteria mandate prospective daily ratings [18].
Q2: Why are prospective daily ratings considered the gold standard for confirming cyclical symptoms?
Prospective daily ratings over at least two symptomatic cycles are required to reliably distinguish between genuine cyclical symptoms and non-cyclical background symptoms, such as a general liability to common psychiatric disorders [18]. This within-participant design allows researchers to confirm that symptoms are confined to the luteal phase and remit post-menses [3] [2].
Q3: What are the practical consequences of relying on provisional (retrospective) versus confirmed (prospective) diagnosis?
Studies relying on provisional diagnosis produce artificially high prevalence rates. Meta-analysis data show the pooled prevalence for provisional diagnosis is 7.7%, but drops to 3.2% for confirmed diagnosis. When restricted to community-based samples using confirmed diagnosis, the prevalence is 1.6%, highlighting the overestimation risk of retrospective methods [3].
Q4: How can researchers address heterogeneity in premenstrual disorders within study designs?
Research suggests the existence of different temporal subtypes of premenstrual dysphoric disorder, likely underpinned by different disease mechanisms [18]. Study designs should plan for this heterogeneity by collecting dense longitudinal data that can later be analyzed using methods like group-based trajectory modeling to identify individual differences in symptom change [18].
Q5: What is the proposed neurobiological mechanism for cyclical symptoms in PMDD?
Premenstrual dysphoric disorder is not a hormonal imbalance but an abnormal sensitivity in the brain to the normal rise and fall of reproductive hormones during the menstrual cycle [19]. This hormonal sensitivity affects neurosteroids like GABA, with sharp drops in the luteal phase potentially removing the brain's "emotional buffer" [20].
Table 1: Prevalence Comparison: Provisional vs. Confirmed PMDD Diagnosis
| Diagnosis Method | Pooled Prevalence | 95% Confidence Interval | Key Characteristics |
|---|---|---|---|
| Provisional Diagnosis | 7.7% | 5.3%–11.0% | Relies on retrospective recall; produces artificially high rates [3] |
| Confirmed Diagnosis | 3.2% | 1.7%–5.9% | Requires prospective daily ratings over ≥2 cycles [3] |
| Confirmed (Community Samples) | 1.6% | 1.0%–2.5% | Lowest heterogeneity (I² = 26%); most accurate estimate [3] |
Table 2: Essential Assessment Tools for Cyclical Symptom Research
| Tool Name | Primary Function | Key Feature | Reference Standard |
|---|---|---|---|
| Daily Record of Severity of Problems (DRSP) | Self-monitoring & prospective daily ratings | Tracks symptom severity daily across cycles | DSM-5-TR criteria [2] |
| Structured Clinical Interview for DSM-IV-TR PMDD (SCID-PMDD) | Diagnostic interview schedule | Standardizes clinical assessment for PMDD | DSM-IV-TR (adaptable for DSM-5-TR) [2] |
| Carolina Premenstrual Assessment Scoring System (C-PASS) | Diagnosis & scoring | Sensitive for predicting sub-threshold PMDD (MRMD) | DSM-5 criteria [2] |
Experimental Protocols
Protocol 1: Prospective Daily Rating for Symptom Confirmation
This protocol is essential for establishing a confirmed diagnosis of premenstrual dysphoric disorder and reducing false positives from retrospective recall [18] [3].
Materials:
- Validated daily rating scale (e.g., Daily Record of Severity of Problems - DRSP)
- Data collection platform (paper diary or secure digital application)
Procedure:
- Screening & Recruitment: Recruit participants of reproductive age who report cyclical mood or behavioral symptoms.
- Baseline Assessment: Conduct a comprehensive assessment to rule out other psychiatric disorders that could explain the symptoms [2].
- Training: Train participants to complete the daily rating scale at the same time each evening, rating each symptom on a defined severity scale.
- Monitoring Period: Participants prospectively rate their symptoms daily for a minimum of two consecutive menstrual cycles [18] [3].
- Data Analysis:
- Confirm Cyclicity: Symptoms must show a statistically significant increase during the luteal phase (typically the 5 days before menses) compared to the post-menstrual follicular phase (typically days 5-10 of the cycle) [2].
- Calculate Severity: The symptoms must cause significant distress and/or functional impairment in the luteal phase [2].
- Diagnosis Confirmation: A confirmed diagnosis requires the above pattern to be documented in most cycles over the preceding year [2].
Protocol 2: Laboratory-Based Hormonal Sensitivity Assessment
This exploratory protocol investigates the potential biological mechanism underlying PMDD, focusing on neural sensitivity to hormonal fluctuations [19].
Materials:
- Gonadotropin-Releasing Hormone (GnRH) agonist (e.g., leuprolide)
- Standardized hormone replacement patches (estradiol and progesterone)
- Functional Magnetic Resonance Imaging (fMRI)
- Validated mood and symptom rating scales
Procedure:
- Participant Groups: Recruit two groups: individuals with confirmed PMDD and healthy controls.
- Hormonal Suppression: Administer a GnRH agonist to both groups to create a stable, low-hormone "baseline" state and suppress the natural menstrual cycle.
- Blinded Hormone Administration: In a cross-over design, participants receive, in a randomized and blinded order:
- A session of hormone replacement (estradiol and progesterone) to mimic the luteal phase hormonal environment.
- A session of placebo.
- Outcome Measurement:
- Neural Activity: Use fMRI to measure brain activity, particularly in fronto-limbic circuits involved in emotional regulation, during emotional tasks in both sessions [2].
- Behavioral & Mood Ratings: Administer mood and symptom scales to quantify subjective changes.
- Data Analysis: Compare the neural and behavioral responses to hormone administration between the PMDD and control groups. A heightened response in the PMDD group indicates an underlying hormonal sensitivity [19].
Signaling Pathways and Workflows
Diagram 1: Hormonal Sensitivity Pathway in PMDD. This diagram contrasts the pathological response in PMDD (top) against a normal physiological response (bottom) to hormonal fluctuations.
Diagram 2: Workflow for Distinguishing Cyclical Symptoms. This protocol is critical for reducing false positives by replacing retrospective recall with prospective monitoring.
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential Materials and Tools for PMDD Research
| Item / Reagent | Function / Application | Key Consideration |
|---|---|---|
| Validated Daily Rating Scales (e.g., DRSP) | Prospective tracking of symptom severity and timing across the menstrual cycle. | Essential for confirming the temporal, cyclical pattern required for diagnosis [2]. |
| Structured Clinical Interviews (e.g., SCID-PMDD) | Standardizes the diagnostic process and ensures consistent application of DSM-5-TR criteria across participants. | Improves reliability and reduces interviewer bias [2]. |
| GnRH Agonists (e.g., Leuprolide) | Creates a hormonally neutral baseline in experimental settings by suppressing the endogenous menstrual cycle. | Allows for controlled, blinded administration of hormones to test the hormonal sensitivity hypothesis [19]. |
| Functional MRI (fMRI) | Measures task-based or resting-state activity in brain circuits (e.g., fronto-limbic) implicated in emotional regulation. | Used to identify neural correlates of abnormal hormonal sensitivity [2]. |
| Salivary or Serum Hormone Kits | Quantifies levels of estradiol, progesterone, and other relevant hormones to correlate with symptom reports. | Confirms the phase of the menstrual cycle and links specific hormonal levels to symptom severity. |
Implementing Gold-Standard Methodologies: A Guide to Prospective Daily Ratings
FAQ: Understanding the Mandates and Implementation
This section addresses common questions from researchers on the specific requirements and practical application of prospective daily ratings under DSM-5 and ICD-11 frameworks.
Q1: What is the specific mandate in DSM-5 and ICD-11 regarding prospective daily ratings for conditions like Premenstrual Dysphoric Disorder (PMDD)?
While the DSM-5 does not prescribe a specific methodology, it emphasizes that a diagnosis of PMDD must be confirmed by prospective daily ratings over at least two symptomatic cycles. This is crucial for establishing a temporal relationship between symptoms and the premenstrual phase and for reducing retrospective recall bias [21]. The ICD-11, similarly, requires that the symptoms be prospectively rated to confirm the diagnosis [22]. The core mandate across both systems is the use of prospective data collection as a validation tool to enhance diagnostic accuracy.
Q2: Why is prospective daily monitoring mandated instead of retrospective recall?
Retrospective recall is highly susceptible to multiple biases, which can lead to false positive reports [21] [23]. Prospective daily ratings mitigate these issues by:
- Minimizing Recall Bias: Capturing data in near real-time reduces the distortion of memory.
- Providing Objective Data: Daily logs create a verifiable record of symptom timing, severity, and cyclicity.
- Differentiating from Other Disorders: The pattern of symptom onset in the luteal phase and remission post-menses is critical for distinguishing PMDD from other mood or anxiety disorders [21]. The upcoming DSM revision also highlights a move towards more dimensional and functional assessments, underscoring the need for precise, longitudinal data [24].
Q3: What are the common technical and participant-related challenges in implementing these daily ratings?
Researchers often encounter several hurdles:
| Challenge Category | Specific Examples |
|---|---|
| Participant Adherence | Missed entries, "backfilling" (entering multiple days at once), early study dropout. |
| Data Quality & Integrity | Inconsistent rating scales, undefined data triggers for protocol violation, data loss during transfer. |
| Technical Issues | Mobile app crashes, synchronization failures with central databases, data security concerns [23]. |
Q4: Our team is designing a new study. What is the minimum monitoring period required by the classifications?
Both DSM-5 and ICD-11 align on a requirement for daily monitoring across a minimum of two symptomatic menstrual cycles to confirm the diagnosis [21] [22]. This allows for the assessment of both the timing and the recurrence of symptoms.
Experimental Protocols for Prospective Data Collection
This section provides a detailed, step-by-step methodology for implementing the mandated prospective daily ratings in a clinical research setting.
Protocol 1: Core Daily Symptom Monitoring Workflow
The following diagram illustrates the primary data collection workflow, from participant engagement to data validation.
- Participant Training and Onboarding: Train participants on the use of the chosen digital platform (e.g., smartphone app, web portal) and the specific rating scales. Ensure they understand the importance of completing ratings at the same time each day.
- Daily Prompt and Data Entry: Implement a system that sends a daily reminder (e.g., push notification) to participants. The interface should be simple and quick to use, prompting them to rate a predefined list of symptoms.
- Data Transmission and Security: Upon submission, data should be encrypted and transmitted to a secure, compliant cloud server or database. This ensures data integrity and participant privacy [23].
- Adherence Monitoring: The system should automatically flag participants with missed entries. An escalation protocol (e.g., reminder notification, email, or SMS) can then be triggered to improve compliance.
- Data Validation and Analysis: After two full cycles, data is analyzed. The key outcome is the confirmation of a pattern where symptoms intensify in the luteal phase and diminish shortly after the onset of menses.
Protocol 2: Data Quality Assurance and Cleaning Pipeline
Raw prospective data often requires cleaning and validation before analysis. This protocol outlines a robust process for ensuring data quality.
- Data Ingestion and Standardization: Consolidate data from all participants into a single, analysis-ready format (e.g., a CSV or database table). Standardize date/time fields and symptom scores.
- Identification of Missing Entries: Calculate adherence rates by identifying days without a submitted rating. Predefine a threshold for protocol violation (e.g., >20% missed entries in a cycle).
- Detection of Implausible Patterns: Use algorithms to detect invalid data patterns, such as:
- Uniformity: Identical scores across all symptoms for many consecutive days.
- Implausible Speed: Multiple days of data submitted within an impossibly short time frame, suggesting "backfilling."
- Data Imputation: For studies with otherwise high-quality data, minor gaps (e.g., single missing days) can be handled using imputation methods. Research indicates that using algorithms that preserve the distribution and correlation of features (e.g., K-nearest neighbors) is superior to simple mean substitution [23].
- Quality Report Generation: Produce a final report summarizing participant adherence, data quality flags, and the imputation methods applied. This ensures transparency in the analysis.
The Scientist's Toolkit: Research Reagent Solutions
The following table details key materials and digital tools essential for executing high-quality prospective daily rating studies.
| Item / Reagent | Function in Research | Key Considerations for Selection |
|---|---|---|
| Digital Data Capture Platform | The primary tool for administering daily surveys, sending reminders, and collecting data. | Choose between custom apps (high control, high cost) or validated commercial eCOA/ePRO platforms. Ensure 21 CFR Part 11 compliance for regulatory studies, robust encryption, and offline capability [25] [26]. |
| Validated Symptom Rating Scales | Standardized instruments to quantify symptom severity prospectively. | Use scales with demonstrated reliability and validity for daily use in PMDD (e.g., Daily Record of Severity of Problems (DRSP)). Ensure translations are culturally validated for multinational trials. |
| Secure Cloud Database | Centralized, secure storage for all collected prospective data. | Must have strong access controls, audit trails, and data backup procedures. Interoperability (e.g., via APIs) with electronic health records (EHRs) or other clinical systems is increasingly valuable [22] [23]. |
| Data Imputation Software | To address the inevitable issue of missing data points in longitudinal studies. | Select statistical software (e.g., R, Python with pandas/scikit-learn) capable of implementing advanced imputation algorithms (e.g., Multiple Imputation by Chained Equations - MICE) that maintain data structure [23]. |
| Menstrual Cycle Tracking Module | To correlate daily symptoms with specific menstrual cycle phases. | Can be integrated into the data capture platform. Should allow participants to log cycle start/end dates. Accuracy is critical for the peri-ovulatory and luteal phase analysis. |
FAQ: Advanced Technical and Diagnostic Issues
Q5: How should we handle significant missing data in prospective ratings?
The approach should be pre-specified in the statistical analysis plan:
- Prevention: Use engaging UI/UX and reminder systems to minimize missing data [26].
- Analysis: Conduct a sensitivity analysis to determine if missingness is random.
- Imputation: For data missing at random, use sophisticated imputation methods (e.g., MICE) as referenced in the data cleaning protocol [23]. If data is not missing at random or exceeds a pre-defined threshold (e.g., >30% in a cycle), consider excluding that cycle from the primary analysis.
Q6: With the development of DSM-6, are these mandates likely to change?
The DSM strategic committee has been formed and is actively working on the next version, estimated for release around 2029 [24]. The focus is on increasing transparency, incorporating biological markers, and improving alignment with ICD-11 [24]. While the core principle of prospective confirmation is unlikely to be abandoned, future mandates may integrate new types of digital biomarkers (e.g., from wearables) alongside daily ratings to provide a more objective and multidimensional assessment [24].
A technical guide for researchers on overcoming the challenges of retrospective bias in menstrually-related mood disorder research.
This resource provides technical guidance for designing robust within-subject prospective studies on premenstrual symptoms, a critical methodology for reducing false positive findings common in retrospective self-reports.
FAQs: Core Study Design Considerations
FAQ 1: Why is a within-subjects prospective design non-negotiable for studying the menstrual cycle?
The menstrual cycle is fundamentally a within-person process. Analyzing it with between-subjects designs conflates variance from changing hormone levels with variance from each individual's baseline traits, lacking validity for assessing cycle effects [27]. Prospective daily monitoring is the gold standard for diagnosis, as it has been established that retrospective self-reports show a remarkable bias toward false positive reports and often do not align with prospective daily ratings [27] [2].
FAQ 2: What is the minimum recommended number of cycles and observations per cycle for a reliable study?
For a reliable assessment, the current diagnostic standard requires prospective daily monitoring for at least two consecutive menstrual cycles [27] [2]. Regarding data points, a basic statistical analysis using multilevel modeling requires at least three observations per person to estimate random effects. However, for more reliable estimation of between-person differences in within-person changes, three or more observations across two cycles is recommended [27].
FAQ 3: How can we minimize participant burden and attrition in lengthy daily studies?
- Leverage Technology: Use online data collection tools and computerized adaptive testing (CAT) to reduce the number of items participants must complete while maintaining measurement precision [28].
- Strategic Sampling: For outcomes that are difficult to collect (e.g., psychophysiological data), strategically select multiple assessment time points across the cycle rather than demanding daily lab visits [27].
- Ensure Compensation: Provide adequate compensation and use methods like lottery bonuses to facilitate and encourage consistent participation over time [28].
FAQ 4: What are the primary threats to internal validity in a within-subjects design, and how can they be controlled?
The main threats are time-related effects and carryover effects [29] [30].
- Time-related effects include history (external events), maturation (natural changes in participants), and subject attrition [29].
- Carryover effects occur when an earlier assessment influences a later one, such as through practice (learning), fatigue, or boredom (order effects) [29] [30].
Control measures include [31] [29]:
- Randomization: Presenting the order of different conditions or tasks in many different possible sequences.
- Counterbalancing: Using a limited number of sequences across the participant group, ensuring each condition appears equally often in each position.
The Scientist's Toolkit: Essential Research Reagents & Materials
Table 1: Key materials and tools for prospective premenstrual symptom studies.
| Item Name | Function & Application | Key Considerations |
|---|---|---|
| Daily Record of Severity of Problems (DRSP) [2] | A self-report daily diary for tracking problem severity. Based on DSM criteria, it is one of the most commonly used tools for prospective daily monitoring. | Essential for establishing the cyclical nature of symptoms required for PMDD diagnosis. |
| Carolina Premenstrual Assessment Scoring System (C-PASS) [27] [2] | A standardized system (with paper worksheets and software macros) for diagnosing PMDD and Menstrually-Related Mood Disorders (MRMD) based on prospective daily ratings. | Sensitive for identifying sub-threshold cases. Critical for ensuring a rigorously defined sample. |
| PROMIS CAT Instruments (e.g., Anger, Depression, Fatigue) [28] | Computerized Adaptive Testing that uses Item Response Theory to provide precise assessment of symptom levels with a minimal number of items (typically 4-12). | Uses a 7-day recall period. Shown to have high ecological validity when compared to daily scores. Reduces participant burden. |
| PROMIS Assessment Center [28] | A free online data collection tool for administering PROMIS instruments and managing longitudinal study data. | Facilitates remote data collection and daily compliance monitoring. |
| Ovulation Test Kits (e.g., Urinary LH tests) [27] | At-home tests to detect the luteinizing hormone (LH) surge, confirming ovulation and allowing for accurate phase determination (follicular vs. luteal). | Crucial for moving beyond crude cycle-day counting and verifying the distinct endocrine phases of the cycle. |
Experimental Protocol: A Standard Workflow for a 2-Cycle Prospective Study
The following diagram outlines the core workflow for a robust within-subjects prospective study, from screening to data analysis.
Prospective Study Workflow
Phase 1: Screening & Recruitment (1-2 Weeks)
- Screening: Identify eligible participants (e.g., regular menstrual cycles, no hormone-based contraception, presenting premenstrual symptoms) [28] [27].
- Informed Consent: Obtain electronic or written informed consent, clearly explaining the commitment to daily tracking.
- Baseline Assessment: Collect demographic data, medical history, and baseline symptom levels.
- Protocol Training: Coach participants thoroughly on how to use the daily diary platform (e.g., PROMIS Assessment Center) and any at-home tests (e.g., ovulation kits) [28].
Phase 2: Prospective Daily Monitoring (Minimum 2 Full Cycles)
- Daily Protocols:
- Symptom Diaries: Participants complete daily ratings (e.g., DRSP) between 6 PM and midnight [28].
- Cycle Tracking: Participants log menstrual bleeding dates.
- Ovulation Confirmation (Recommended): Participants use at-home urinary LH test kits for one or both cycles to confirm ovulation and enable precise phase calculation [27].
- Weekly Check-ins (Optional): Administer additional brief assessments, such as PROMIS CAT instruments, to compare with aggregated daily scores and reduce item burden [28].
- Compliance Monitoring: Research staff should monitor data submission daily and contact participants promptly if assessments are missed to minimize attrition and missing data [28].
Phase 3: Data Preparation & Analysis
- Data Cleaning: Prepare the dataset for analysis, identifying input errors and assessing completeness.
- Cycle Phase Coding: Do not rely on a standard 28-day cycle model. Use the first day of menses and (if available) the day of ovulation to back-calculate each participant's unique cycle phases (e.g., late follicular, periovulatory, mid-luteal, perimenstrual) for analysis [27].
- Statistical Modeling: Use multilevel modeling (random effects modeling) to account for the nested structure of the data (repeated measures within individuals) and to test hypotheses about within-person changes across cycle phases [27].
Troubleshooting Common Experimental Issues
Problem: High participant attrition during the second cycle of daily tracking.
- Potential Cause: Participant burden and diary fatigue.
- Solution: Implement tiered compensation that increases upon completion of the second cycle. Utilize brief, adaptive weekly measures (like PROMIS CAT) in conjunction with daily diaries to maintain engagement without compromising data quality [28].
Problem: Inconsistent or missing daily diary entries.
- Potential Cause: Forgetfulness or lack of motivation.
- Solution: Implement automated daily reminder notifications (email/SMS). Maintain regular, supportive contact from research staff. For critical but hard-to-collect data (e.g., lab-based outcomes), schedule a limited number of in-person visits timed to specific, confirmed cycle phases rather than relying on daily lab visits [27].
Problem: Data shows no clear cyclical pattern of symptoms.
- Potential Cause 1: Incorrect phase alignment due to variable cycle lengths.
- Solution: Code phases based on each participant's confirmed ovulation and menses dates, not on a presumed 28-day cycle [27].
- Potential Cause 2: The sample may include participants with premenstrual exacerbation (PME) of an underlying chronic disorder rather than a pure cyclical disorder like PMDD, obscuring the data pattern.
- Solution: Use a validated scoring system like C-PASS during screening and data analysis to carefully distinguish PMDD from PME and other non-cyclical disorders [27] [2].
Reference Tables: Quantitative Guidelines
Table 2: Key characteristics of the menstrual cycle phases for study planning (based on a meta-review) [27].
| Cycle Phase | Approximate Cycle Days | Average Length (Days) | Hormonal Profile |
|---|---|---|---|
| Follicular Phase | Day 1 (menses start) to Ovulation | 15.7 (SD = 3.0) | Low & stable Progesterone (P4); Estradiol (E2) rises gradually then spikes before ovulation. |
| Luteal Phase | Day after Ovulation to day before next menses | 13.3 (SD = 2.1) | P4 and E2 rise gradually, peak mid-phase, then fall rapidly perimenstrually if no pregnancy. |
Table 3: Comparison of primary assessment tools for premenstrual symptoms [27] [2].
| Tool Name | Format | Primary Use | Key Advantage |
|---|---|---|---|
| Daily Record of Severity of Problems (DRSP) | Prospective Daily Diary | Tracking daily symptom severity & establishing cyclicity | Directly maps onto DSM-5-TR diagnostic criteria for PMDD. |
| Carolina Premenstrual Assessment Scoring System (C-PASS) | Scoring System & Software Macros | Diagnosing PMDD & MRMD from daily ratings | Identifies sub-threshold cases; ensures sample purity for research. |
| PROMIS CAT (e.g., Anger, Depression) | Computerized Adaptive Test (Weekly) | Precise, low-burden assessment of specific domains | High ecological validity correlated with daily scores; reduces participant burden. |
Selecting and Validating Prospective Data Collection Instruments
Frequently Asked Questions
FAQ 1: Why is prospective data collection so critical in premenstrual syndrome (PMS) research? Retrospective self-report measures of premenstrual changes in affect have a remarkable bias toward false positive reports and do not converge better than chance with prospective daily ratings [27]. Beliefs about PMS can also influence retrospective measures [27]. Therefore, prospective daily monitoring for at least two consecutive menstrual cycles is required for a reliable diagnosis of premenstrual dysphoric disorder (PMDD) and is essential for reducing false positive reports in research [27] [32].
FAQ 2: What is the most common design flaw when treating the menstrual cycle as a variable? The menstrual cycle is fundamentally a within-person process. A common flaw is treating cycle phase or corresponding hormone levels as a between-subject variable, which conflates within-subject variance with between-subject variance. The gold-standard approach is a repeated measures design where the same participant is assessed across multiple cycle phases [27].
FAQ 3: When should I develop a new instrument instead of using an existing one? Developing a new instrument is generally not recommended unless there are no existing tools to measure your phenomenon of interest or the available ones have huge and confirmed limitations. The process requires considerable effort and time, and the new instrument may have flaws similar to or greater than existing ones, with the additional drawback of preventing comparison with previous studies [33].
FAQ 4: How many data points per participant are needed to model within-person effects across the cycle? Multilevel modeling (or random effects modeling) requires at least three observations per person to estimate random effects of the cycle. For more reliable estimation of between-person differences in within-person changes, three or more observations across two cycles is recommended [27].
Troubleshooting Guides
Problem 1: Choosing an Inappropriate Data Collection Instrument
Symptoms:
- Your collected data cannot be compared with other studies on the same topic.
- The instrument does not accurately capture the core symptoms of the population you are studying.
- The instrument's validity and reliability are unknown or poor.
Solutions:
- Conduct a Thorough Literature Search: Perform a broad search across bibliographic databases (e.g., PubMed) and other scientific fields to identify existing instruments. Also, contact researchers in the area to inquire about unpublished instruments ("gray literature") [33].
- Select Instruments with Strong Psychometric Properties: Prioritize instruments that have established validity (they measure what they intend to) and reliability (they produce consistent results) [33] [34].
- Use a Core Set of Discriminating Symptoms: For PMS research, evidence suggests that a reduced set of symptoms can effectively discriminate PMS cases. Using a focused instrument reduces participant burden. The table below outlines core symptoms identified in one study [5].
Table 1: Core Symptoms for Discriminating PMS in Prospective Daily Diaries [5]
| Core Symptom | Category |
|---|---|
| Anxiety/Tension | Emotional |
| Mood Swings | Emotional |
| Decreased Interest in Activities | Emotional |
| Appetite/Food Cravings | Somatic |
| Cramps | Somatic |
| Aches | Somatic |
Problem 2: Failing to Adequately Validate Your Instrument
Symptoms:
- Low participant comprehension of questions leads to poor-quality data.
- The instrument's scores are not meaningful or useful for answering your research question.
- The instrument lacks credibility with the scientific community.
Solutions:
- Employ a Mixed-Methods Validation Approach: Combine quantitative and qualitative procedures to collect robust construct validity evidence. Analyze quantitative ratings alongside qualitative comments from participants to evaluate congruence, convergence, and credibility [35].
- Follow a Structured Validation Process: Adhere to established phases for instrument development and validation, as outlined in the workflow below.
- Conduct a Pilot Study: Administer the instrument to a small, representative sample. Use the data to test internal consistency (e.g., with Cronbach's alpha) and gather feedback for refinement [36] [37].
Instrument Development and Validation Workflow
Problem 3: Incorrectly Defining the Menstrual Cycle Phases
Symptoms:
- Inability to replicate your own findings or those of others.
- High variability in data due to misaligned cycle phases between participants.
- Confusion in the literature and frustrated meta-analyses.
Solutions:
- Use a Standardized Vocabulary and Definition: Clearly define and report how you determined cycle phases. The first day of menses is cycle day 1. The follicular phase is from menses onset through ovulation. The luteal phase is from the day after ovulation until the day before the next menses [27].
- Account for Cycle Length Variability: The luteal phase is more consistent in length (average 13.3 days) than the follicular phase (average 15.7 days). Most variance in total cycle length is due to follicular phase variance. Do not assume a standard 28-day cycle for all participants [27].
- Measure Ovulation or Use a Standardized Counting Method: For the highest accuracy, confirm ovulation using testing kits or hormone measurement. If this is not feasible, use a validated counting method (e.g., the onset of menses minus 13 days) to estimate the start of the luteal phase [27].
Menstrual Cycle Phases and Symptom Onset
The Scientist's Toolkit: Key Research Reagents & Materials
Table 2: Essential Materials for Prospective PMS Research
| Item | Function in Research |
|---|---|
| Prospective Daily Diary | The primary tool for data collection. Used by participants to record symptom severity daily across the menstrual cycle to avoid retrospective recall bias. Example: Penn Daily Symptom Report (DSR) [5]. |
| Hormone Assay Kits | Used to measure levels of ovarian hormones (e.g., estradiol (E2), progesterone (P4)) from saliva or blood samples. Critical for objectively confirming menstrual cycle phase and examining biological mechanisms [27]. |
| Ovulation Prediction Kits | At-home test kits that detect the luteinizing hormone (LH) surge in urine, which precedes ovulation. Essential for precisely defining the transition from the follicular to the luteal phase in a study [27]. |
| Validated Scoring System (e.g., C-PASS) | A standardized system (like the Carolina Premenstrual Assessment Scoring System) used to diagnose PMDD or premenstrual exacerbation (PME) based on prospective daily ratings. Helps screen samples for confounding cyclical mood disorders [27]. |
| Statistical Software with MLM Capability | Software (e.g., R, SAS) capable of running multilevel models (MLM) or random effects models. Necessary for correctly analyzing nested, repeated measures data where observations (symptom scores) are nested within individuals [27]. |
Technical Support Center: Troubleshooting Guides and FAQs
This section provides solutions to common problems encountered during research studies on reducing false positive retrospective premenstrual reports.
Frequently Asked Questions (FAQs)
Q: Our participant attrition rate is high, especially around the menstrual phase. How can we improve adherence?
- A: Implement a training management system (TMS) to automate and personalize participant communication [38]. Schedule automated, pre-written reminder emails and survey invitations for different cycle phases to reduce the administrative burden on staff and ensure consistent, low-effort contact with participants [38].
Q: We observe significant data variability in self-reported symptoms. How can we improve data quality?
- A: Standardize your data collection instruments. Use validated tools like the Menstrual Distress Questionnaire (MDQ) and the Menstrual Cycle-Related Work Productivity Questionnaire, which are specifically designed to measure the prevalence and intensity of hormonal-related symptoms and their impact [39]. Ensure all researchers are trained in the standardized administration of these tools.
Q: Our team struggles with inconsistent experimental protocols across different researchers. What is the best way to fix this?
- A: Develop and codify your workflows using a workflow management system [40]. Document every step of your experimental protocols, from participant onboarding to data processing, in a centralized platform. This ensures everyone follows the same steps and actions regardless of their role, which is a key practice in effective workflow management [40].
Q: How can we efficiently track which participants are in which phase of their cycle for timely data collection?
- A: Utilize the participant management features of a TMS [38]. The system can capture participant information through online registration forms and store it in a centralized database. You can then use this system to track participant progress and link data to specific cycle phases, sending automated communication based on triggers [38].
Q: Our data processing is slow, creating a backlog. How can we speed this up?
- A: Identify and prioritize data processing workflows. Look for opportunities to automate routine tasks, such as data entry and initial quality checks, using workflow software. Automated routing ensures that steps such as approval or data validation happen without human intervention, significantly speeding up the process [40].
Experimental Protocols and Workflow Visualization
This section outlines a core methodology for data collection and management, with a visual representation of the workflow.
Detailed Methodology for Prospective Longitudinal Data Collection
This protocol is designed to minimize recall bias, a key source of false positives in retrospective reports.
- Objective: To collect real-time data on hormonal-related symptoms and functional impacts across the menstrual cycle.
- Participant Recruitment:
- Eligibility: Females of reproductive age (e.g., 18-45), with regular menstrual cycles or contraceptive-driven cycles, fluent in the study language.
- Exclusion Criteria: Pregnancy, menopause, hysterectomy, or conditions that would prevent reliable self-reporting [39].
- Informed Consent: Obtain written informed consent approved by an Institutional Review Board (IRB) [39].
- Data Collection Instruments:
- Demographics & Menstrual History: Collect age, BMI, menarche age, cycle characteristics, and contraceptive use [39].
- Menstrual Distress Questionnaire (MDQ): A validated 47-item tool measuring the presence and intensity of symptoms rated on a five-point scale. It yields eight subscale scores and a total distress score [39].
- Work Productivity Questionnaire: A modified version of the Menstrual Cycle-Related Work Productivity Questionnaire, assessing perceptions of concentration, efficiency, energy levels, and mood at work across cycle phases [39].
- Procedure:
- Onboarding: Enroll participants and train them on using the data collection platform (e.g., a TMS portal or a dedicated app).
- Phase-Based Triggering: The system automatically sends the MDQ and productivity questionnaire based on participant-reported cycle phase (e.g., pre-bleed, bleed, late follicular, early luteal) [39].
- High-Frequency Sampling: Participants complete assessments multiple times per cycle phase to capture intra-phase variability.
- Data Submission: Participants submit responses through a secure online portal.
- Automated Follow-up: The system sends automated thank-you communications and survey invitations to improve participant experience and retention [38].
Experimental Workflow Diagram
The following diagram visualizes the core operational workflow from participant training to data management.
Automated Data Collection Workflow - This diagram illustrates the streamlined process from participant onboarding to data analysis, highlighting automated phase-based triggers.
Data Presentation
The following table synthesizes quantitative findings on how symptoms and productivity fluctuate across the menstrual cycle, based on cross-sectional questionnaire data [39].
| Cyclical Hormone Phase | Relative Symptom Severity | Perceived Work Productivity | Key Data Collection Focus |
|---|---|---|---|
| Bleed Phase (Menstrual) | Most Severe Disturbances | Most Negative | High-frequency MDQ sampling; productivity impact on concentration and energy levels [39]. |
| Pre-Bleed Phase (Premenstrual) | Severe Disturbances | Negative | MDQ subscales for negative affect/water retention; productivity impact on mood and coworker relationships [39]. |
| Early Luteal Phase | Less Severe | Positive | Baseline MDQ measures; positive productivity trends in efficiency and interest [39]. |
| Late Follicular Phase | Least Severe | Most Positive | Use as a within-subject control; track positive productivity measures [39]. |
The Scientist's Toolkit: Research Reagent Solutions
This table details essential materials and tools for conducting research in this field.
| Item | Function in Research |
|---|---|
| Validated Questionnaires (MDQ) | Measures the presence and intensity of cyclical menstrual symptoms with high reliability, reducing measurement error [39]. |
| Training Management System (TMS) | A centralized platform to manage participant communication, schedule assessments, track progress, and automate follow-ups, streamlining study operations [38]. |
| Workflow Management Software | Allows researchers to codify and automate study protocols, from data entry to quality checks, ensuring consistent and unambiguous procedures across the team [40]. |
| Secure Centralized Database | A critical repository for all participant data, ensuring integrity, security, and facilitating streamlined data processing and analysis [38]. |
| Low-Contrast Color Palettes | For creating participant-facing materials and internal dashboards, ensuring text has enhanced contrast against backgrounds for readability and compliance with accessibility standards (e.g., WCAG AAA) [41] [42]. |
Overcoming Practical Hurdles: Ensuring Adherence and Data Quality in Longitudinal Studies
Mitigating Participant Burden to Improve Long-Term Adherence
Troubleshooting Guides
Guide 1: Addressing Low Questionnaire Completion Rates
Problem: Participants are failing to complete patient-reported outcome (PRO) questionnaires, or data is missing.
- Potential Cause 1: High Cognitive Burden
- Potential Cause 2: Administrative Burden
- Potential Cause 3: Lack of Perceived Relevance
Guide 2: Managing Participant Attrition in Longitudinal Studies
Problem: Participants are dropping out of the study or being lost to follow-up.
- Potential Cause 1: Logistical and Financial Barriers
- Potential Cause 2: Weak Participant-Investigator Rapport
- Diagnosis: Participants feel like a number and lack a personal connection to the study team. [48]
- Solution: Strengthen relational bonds.
- Potential Cause 3: Forgetfulness and Scheduling Conflicts
Guide 3: Overcoming Medication Non-Adherence
Problem: Participants are not taking the study medication as prescribed, jeopardizing trial validity.
- Potential Cause 1: Complex Dosing Schedules
- Potential Cause 2: Forgetfulness
- Potential Cause 3: Inadequate Understanding
Frequently Asked Questions (FAQs)
Q1: What is the single most effective strategy for retaining participants in long-term studies? A: Evidence suggests there is no single "magic bullet." However, systematic reviews indicate that strategies focused on reducing participant burden (e.g., flexible data collection, logistical support) are significantly associated with higher retention rates. Building a strong, respectful rapport between the research team and the participant is also consistently highlighted as a critical success factor. [48] [50]
Q2: How can I balance the need for comprehensive data with the risk of overburdening participants? A: Carefully balance the quantity and quality of data required against the potential burden. [43] [46] This involves:
- Justifying every data point collected. [46]
- Involving patients and clinicians in the design of the assessment schedule to ensure it captures clinically relevant periods without being excessive. [46]
- Selecting the most relevant PROs to avoid administering multiple lengthy questionnaires. [43]
Q3: Are financial incentives effective for improving retention, and are they ethical? A: Incentives like travel reimbursement can help overcome participation barriers. [48] However, all incentives must be reviewed and approved by an Ethics Committee to ensure they are not unduly influential or coercive. The amount and conditions must be carefully considered to avoid exploiting participants' financial needs. [48]
Q4: We use electronic PROs (ePROs) to reduce burden, but our older participants struggle with the technology. What can we do? A: To ensure equity and avoid alienating less tech-savvy or underserved groups, employ a hybrid approach. Offer both electronic and paper-based options. [44] This "low-tech" alternative is crucial for maintaining inclusivity and preventing bias in your sample. [43] [44]
Q5: How does participant burden specifically relate to reducing false positives in retrospective self-reports, such as in premenstrual symptom research? A: High participant burden can exacerbate recall errors and biased reporting in retrospective studies. [43] Burdened or fatigued participants are less likely to provide careful, accurate recollections, potentially leading to increased measurement error. Mitigating burden through shorter, more focused recall periods and user-friendly data collection methods can improve data quality and reduce this source of false positives.
Data Presentation
Table 1: Retention Rates Achieved in Major Clinical Trials
Table showing that high retention is achievable with effective strategies.
| Name of the Study | Year Conducted | Number of Study Participants | Retention Rate (%) |
|---|---|---|---|
| DEVOTE [48] | 2013-2014 | 7,637 | 98% |
| PIONEER 6 [48] | 2017-2019 | 3,418 | 100% |
| PIONEER 8 [48] | 2017-2018 | 731 | 96% |
| SUSTAIN 6 [48] | 2013 | 3,297 | 97.6% |
| LEADER [48] | 2010-2015 | 9,340 | 97% |
| INDEPENDENT [48] | 2015-2019 | 404 | 95.5% |
Table 2: Effectiveness of Broad Retention Strategy Categories
Meta-analysis data on how different types of strategies impact retention in longitudinal studies. [50]
| Strategy Category | Description | Impact on Retention Rate (vs. No Strategy) |
|---|---|---|
| Barrier-Reduction | Strategies that reduce logistical, financial, and time burdens on participants (e.g., flexible data collection, travel reimbursement). | Retained 10% more of their sample [50] |
| Follow-up/Reminder | Strategies involving tracking and reminding participants of appointments (e.g., reminder calls, letters). | Associated with losing an additional 10% of the sample* [50] |
| Community-Building | Strategies that foster a sense of connection and partnership (e.g., building rapport, community advisory boards). | Not specified |
This negative association may reflect that studies with inherently higher risk of attrition feel a greater need to implement intensive reminder strategies.
Experimental Protocols
Protocol 1: Implementing a Multi-Faceted Retention Strategy for a Longitudinal Cohort
This protocol is adapted from successful longitudinal studies, including the PAIR project, which focused on high-adversity populations. [47]
1. Objective: To achieve a participant retention rate of >90% over multiple waves of data collection in a longitudinal study.
2. Materials:
- Participant tracking database
- Communication tools (phone, email, postal mail)
- Budget for incentives and reimbursement
- Staff trained in interpersonal communication
3. Methodology:
- Pre-Recruitment:
- Stakeholder Engagement: Form a community advisory board and involve patient partners in the study design phase to ensure the protocol is acceptable and relevant. [46] [47]
- Protocol Optimization: Design the study to minimize burden. This includes simplifying questionnaires, offering flexible visit schedules (weekends/evenings), and planning for mobile or at-home visits. [50] [45]
- At Enrollment:
- Rapport Building: The study coordinator spends significant time building a personal relationship with the participant, emphasizing their value to the study. [48]
- Clear Communication: Set clear expectations about the study timeline and commitment. Provide a 24/7 contact number for the study team. [48]
- Collect Collateral Contacts: Secure multiple forms of contact information (e.g., participant's phone, email, and a relative's phone) for future tracing. [47]
- During the Study:
- Ongoing Engagement: Maintain contact between waves with non-intrusive methods like a study newsletter, birthday cards, or periodic check-in calls. [48] [47]
- Flexible Data Collection: Be prepared to conduct shorter versions of assessments or collect data via alternative methods (phone, online) if a participant is facing difficulties. [50] [44]
- Appointment Management: Send reminder calls/texts 3 days and 1 day before appointments. Implement an "overscheduling" strategy to account for no-shows. [47]
- At Each Visit:
Protocol 2: Cognitive Debriefing for PRO Measure Selection
1. Objective: To select and adapt PRO measures that minimize cognitive burden and are relevant to the target population, thereby improving data quality and adherence.
2. Materials:
- Candidate PRO measures
- Interview guide
- Audio recorder and transcription service
- Sample of participants from the target population (5-10 is often sufficient for this purpose)
3. Methodology:
- Step 1: Participant Recruitment: Recruit a small sample that represents the intended study population, including diversity in education, age, and disease severity. [43]
- Step 2: Think-Aloud Interview: Administer the PRO measure to the participant. Ask them to verbalize their thought process as they read each question, decide on their answer, and navigate the response options. [43]
- Step 3: Probing: After the think-aloud, ask specific probe questions:
- Step 4: Analysis and Iteration: Transcribe and analyze interviews for themes related to confusion, irrelevant content, and burden. Use this feedback to select the final measure, modify items, or shorten the instrument. [43]
Strategy Implementation Workflow
The Scientist's Toolkit: Research Reagent Solutions
Table of key resources and their functions for mitigating participant burden.
| Item / Solution | Function in Mitigating Burden |
|---|---|
| Short-Form PRO Measures | Validated, abbreviated versions of longer questionnaires that capture key concepts with fewer items, reducing time and cognitive load. [43] |
| Adaptive Testing (CAT) Platforms | Software that uses algorithms to select the most informative questions for each individual, minimizing the number of questions needed for precise measurement. [44] |
| Electronic PRO (ePRO) Systems | Platforms (apps, web portals) that allow flexible, asynchronous data collection on a participant's own device, reducing logistical barriers. [44] |
| Telehealth/Telemedicine Kits | Tools for remote visits (e.g., secure video conferencing, at-home vital signs monitors) to eliminate travel burden. [45] |
| Participant Relationship Management (PRM) Database | A centralized system to track participant contact details, communication history, and preferences, enabling personalized follow-up and reminders. [47] |
| Digital Adherence Tools | Smart pill bottles, mobile app reminders, and sensors that provide objective adherence data and prompts without intrusive methods. [49] |
Leveraging Digital Tools and Mobile Platforms for Real-Time Data Capture
Technical Support Center
Troubleshooting Guides
Guide 1: Resolving Mobile Data Synchronization Failures
Problem: Collected data on mobile devices fails to sync with central database upon reconnecting to the internet.
Diagnosis Steps:
- Verify that the offline data collection feature was enabled before going offline [51].
- Check available storage space on the mobile device [52].
- Confirm the device has stable internet connection (Wi-Fi or cellular data) [52].
- Review sync logs within the mobile app for error codes [52].
Resolution:
- Manually trigger synchronization from the app's main menu [51].
- If storage is low, clear cache or export/delete completed records [52].
- For persistent failures, uninstall and reinstall the mobile app, then relogin [52].
Prevention:
- Enable automatic sync in app settings when on Wi-Fi [51].
- Regularly update the mobile app to the latest version [52].
Guide 2: Addressing Real-Time Data Capture Gaps
Problem: Gaps or missing data points in continuous real-time data streams [52].
Diagnosis Steps:
- Check device buffer size configuration [52].
- Verify sufficient network bandwidth for data transmission volume [52].
- Review device power settings preventing background data transmission [52].
Resolution:
- Increase buffer allocation in application settings [52].
- Configure power settings to allow background data activity [52].
- Implement data compression for large media files (photos, audio) [51].
Prevention:
- Conduct pre-deployment network requirement analysis [52].
- Test under real-world conditions before full study rollout [52].
Frequently Asked Questions (FAQs)
Q: How does real-time data capture reduce false positives in retrospective premenstrual symptom reports?
A: Retrospective recall relies on memory, which is highly susceptible to bias and inaccuracy [53]. Real-time data capture eliminates this memory distortion by capturing symptoms as they occur, providing objective, time-stamped data that more accurately represents symptom timing, severity, and duration relative to the menstrual cycle [19].
Q: What types of data beyond text can be captured to enrich PMS research data?
A: Modern mobile platforms support multimedia and sensor data capture including [51]:
- Photos and videos for visual documentation
- GPS coordinates for geotagged environmental context
- Audio recordings for vocal tone or descriptive context
- Digital signatures for consent documentation
- Barcode or RFID scans for medication or sample tracking
Q: What security measures are essential for handling sensitive PMS symptom data?
A: Essential security features include [51]:
- Data encryption both during transmission and storage
- Secure user authentication protocols
- Compliance with healthcare data protection regulations (e.g., HIPAA)
- Robust backup systems to prevent data loss
Q: How do I select the right mobile data collection tool for a longitudinal PMS study?
A: Evaluate tools based on these criteria [51] [54]:
- Offline functionality and sync reliability
- Form logic capabilities (skip patterns, validation)
- Support for multimedia capture
- Integration options with your analysis software
- Scalability for study duration and participant numbers
- Security features for sensitive health data
Experimental Protocols for Digital Data Capture
Protocol 1: Ecological Momentary Assessment (EMA) Implementation
Purpose: To capture premenstrual symptoms in real-time within natural environments, reducing recall bias [53].
Materials:
- Mobile devices with data collection app installed [51]
- Secure cloud database for data aggregation [51]
- Mobile data collection platform (e.g., Fulcrum, KoboToolbox) [54]
Procedure:
- Configure digital assessment forms:
Participant training:
- Distribute configured mobile devices to participants
- Demonstrate daily symptom logging procedure
- Test offline functionality in controlled environment
Data collection:
Data synchronization:
- Devices automatically sync when internet available [51]
- Central database aggregates all participant data
- Automated quality checks flag incomplete/missing data
Validation: Compare EMA data with retrospective recall at end of cycle to quantify recall bias [53].
Protocol 2: Multi-Modal Symptom Capture Methodology
Purpose: To triangulate subjective reports with objective behavioral and physiological measures [19].
Materials:
- Mobile data collection platform supporting multimedia [51]
- Wearable activity trackers (compatible with platform)
- Digital scales for symptom self-reporting
Procedure:
- Subjective data collection:
Objective data integration:
- Sync wearable data (sleep, activity, heart rate variability)
- Capture voice samples for vocal analysis [51]
- Enable photo capture for visible symptoms (bloating, skin)
Temporal alignment:
- All data streams tagged with synchronized timestamps
- Menstrual cycle phase calculated based on onset reporting
- Data aggregated by cycle day for analysis
Analysis: Compare objective behavioral patterns with subjective reports to identify discrepancies [19].
Data Collection Tools Comparison
Table 1: Mobile Data Collection Platform Features
| Platform | Best For | Offline Support | Data Types | Pricing | Integration Options |
|---|---|---|---|---|---|
| Fulcrum | Geolocation with custom maps [54] | Yes [54] | Text, photos, GPS, signatures, barcodes [54] | From $15/month for 5 users [54] | Esri maps, Zapier, API [54] |
| FastField | Overall ease of use [54] | Yes [54] | Text, photos, signatures, scans [54] | $25/user/month [54] | API, Zapier, Slack [54] |
| KoboToolbox | Free option for academic use [54] | Yes [54] | Text, GPS, photos, surveys [54] | Free up to 10,000 submissions [54] | API, webhooks [54] |
| Jotform | Form-building options [54] | Limited | Text, payments, signatures [54] | Free for 5 forms; paid from $39/month [54] | Extensive third-party integrations [54] |
Table 2: Mobile Analytics Tools for Behavioral Data
| Tool | Best For | Key Features | Pricing | Platform Compatibility |
|---|---|---|---|---|
| UXCam | Product analytics with session replay & heatmaps [55] | Session recordings, heatmaps, funnel analytics [55] | Free trial / Pricing upon request [55] | iOS, Android, React Native, Flutter [55] |
| Firebase Analytics | Free mobile analytics [55] | Event tracking, audience segmentation, real-time data [55] | Free [55] | iOS, Android [55] |
| Mixpanel | User interaction and retention [55] | Funnel analysis, retention reports, cohort analysis [55] | Free / Paid (starts at $28/month) [55] | iOS, Android, Web [55] |
| Amplitude Analytics | Predictive mobile analytics [55] | Behavioral analytics, predictive metrics [55] | Free up to 10M actions/month [55] | iOS, Android [55] |
Research Reagent Solutions
Table 3: Essential Digital Research Materials
| Item | Function | Implementation Example |
|---|---|---|
| Validated Digital Scales | Standardized symptom measurement | Program PSST and DASS-42 into mobile forms for consistent administration [53] |
| Geolocation Services | Environmental context capture | Track location to correlate symptoms with environmental stressors [51] |
| Time-Stamping Module | Precise temporal data | Automatically tag all entries with collection time to establish symptom chronology [51] |
| Data Encryption Protocol | Security of sensitive health data | Protect participant privacy and maintain regulatory compliance [51] |
| API Integration Framework | System interoperability | Connect mobile data collection with analysis software (R, Python, SPSS) for streamlined workflows [54] |
| Multimedia Capture Tools | Rich contextual data | Photo documentation of physical symptoms; audio recording of qualitative descriptions [51] |
Methodology Visualization
EMA Methodology Workflow
Multi-Modal Data Capture
Recall Bias Assessment
Identifying and Correcting for Common Data Integrity Issues
Frequently Asked Questions
What is data integrity and why is it critical in scientific research? Data integrity refers to the accuracy, completeness, consistency, and reliability of data throughout its entire lifecycle, from creation and processing to storage and retrieval [56] [57]. In scientific research, it is the cornerstone of validity and reproducibility. Compromised data integrity can lead to false conclusions, jeopardize patient safety in clinical settings, and undermine trust in scientific findings [58]. Within the specific context of premenstrual dysphoric disorder (PMDD) research, high data integrity is essential to avoid false-positive retrospective reports and ensure that biological mechanisms are accurately identified [59].
What are the most common threats to data integrity in a research environment? Common threats can be categorized as follows [57] [58]:
- Human Error: Manual data entry mistakes, accidental file deletions, and inadequate documentation.
- Technical Failures: Software crashes, hardware malfunctions, and network disruptions leading to data loss or corruption.
- Process Failures: Inadequate data management systems, lack of validation procedures, and insufficient auditing.
- Methodological Pitfalls: In study contexts like PMDD research, a primary threat is the reliance on retrospective self-reporting for diagnosis, which can have a false-positive rate as high as 60% [59].
How can our research team reduce errors from manual data entry? Automating data collection is the most effective strategy. A 2025 study demonstrated that Large Language Models (LLMs) can extract clinical classification data from unstructured text with significantly higher accuracy than manual registry entry, which had error rates between 5.5% and 17.0% [60]. For data that must be entered manually, using Electronic Data Capture (EDC) systems with built-in real-time validation checks can minimize human error [58].
What is a data dictionary and why do we need one? A data dictionary is a separate file that explains all variable names, the coding of their categories, their units, and the context of data collection [61]. It is crucial for ensuring interpretability and consistency, especially in long-term or multi-researcher projects. For example, it prevents confusion by explicitly defining codes like "1 = high school diploma, 2 = Bachelor’s degree" [61].
What are the key principles for maintaining data integrity (ALCOA+)? The ALCOA+ framework provides a foundational set of principles for trustworthy data [56]:
- Attributable: Data must clearly indicate who created it.
- Legible: Data must be readable and permanent.
- Contemporaneous: Data should be recorded at the time of the activity.
- Original: The first recorded capture of the data must be preserved.
- Accurate: Data must be error-free and truthful.
- Complete: All data must be present.
- Consistent: Data must be recorded in a stable sequence.
- Enduring: Data must be maintained for its required lifecycle.
- Available: Data must be accessible for review and audit.
Troubleshooting Guides
Issue 1: High Rate of False-Positive Retrospective Reports in PMDD Studies
Problem Description In PMDD research, a common data integrity issue is the inflation of prevalence rates and false-positive diagnoses due to reliance on retrospective symptom recall, rather than prospective daily monitoring [59].
Identification and Diagnosis
- Symptom: A study finds a PMDD prevalence rate of 34% using a retrospective questionnaire, which is inconsistent with lower rates from more rigorous methods [59].
- Diagnosis: Comparison with the DSM-5-TR criteria, which mandates at least two cycles of prospective daily symptom ratings using standardized tools (e.g., the Daily Record of Severity of Problems), will reveal the data integrity issue [59].
Step-by-Step Correction Protocol
- Shift to Prospective Data Collection: Immediately halt reliance on retrospective data for formal diagnosis. Implement a protocol requiring a minimum of two symptomatic cycles of prospective daily ratings [59].
- Use Standardized Tools: Provide research participants with a validated tool like the Daily Record of Severity of Problems (DRSP) for daily tracking [59].
- Define Clear Thresholds: Pre-define the specific criteria for a positive PMDD diagnosis based on the prospective data (e.g., a specific increase in symptom scores in the luteal phase versus the follicular phase).
- Re-baseline Data: Re-assess your study cohort using the new prospective methodology to establish a diagnostically accurate dataset.
Prevention Strategy Incorporate the requirement for prospective daily monitoring directly into your study's initial design and data management plan. Educate all research staff on the high false-positive rate associated with retrospective recall and the DSM-5-TR's diagnostic standards [59].
Issue 2: Internal Inconsistencies in Registered Data
Problem Description Data entries within the same dataset conflict with each other. For example, in a cancer registry, the "radiological findings of lymph node enlargement" may conflict with the registered "clinical N (cN)" classification [60].
Identification and Diagnosis
- Symptom: A query of the dataset reveals logical mismatches between linked parameters.
- Diagnosis: Perform internal consistency checks by cross-referencing related data fields. One study found a 3.3% inconsistency rate through such checks [60].
Step-by-Step Correction Protocol
- Identify All Related Parameters: Map out which data points in your study are logically connected (e.g., a radiological finding and its corresponding clinical classification).
- Run Automated Logic Checks: Implement automated scripts or database rules to flag records where related parameters do not align.
- Trace to Source Documentation: For every flagged record, return to the original source document (e.g., the radiology report) to verify the correct information.
- Correct the Registry: Update the database with the verified, accurate data.
Prevention Strategy Build automated validation rules into your data entry system (EDC) that prevent the entry of logically conflicting data. For example, the system can automatically populate the cN field based on the logical N finding, requiring an override and an audit trail comment for any manual exception [58] [60].
Issue 3: General Data Handling and Processing Errors
Problem Description This encompasses a range of issues including incorrect data transformation, combining information that should be separate, and losing raw data [61].
Identification and Diagnosis
- Symptom: Inability to reproduce data processing steps, or discovering that raw data has been overwritten by processed data.
- Diagnosis: A lack of a clear audit trail and version control for data files.
Step-by-Step Correction Protocol
- Restore from Raw Data: Always return to the saved, unprocessed raw data to restart processing [61].
- Script All Processing: Use scripts (e.g., in R or Python) for all data transformation steps instead of manual point-and-click operations, ensuring the process is documented and reproducible [61].
- Avoid Combining Data: Store information in its most granular form. For example, record "first name" and "last name" in separate columns, rather than a single "full name" column, as joining information is easier than separating it [61].
- Version Control: Use version control systems (e.g., Git) for your data processing scripts and manually version data files if a formal system is not used [61].
Prevention Strategy
- Define Strategy Early: Plan the study, data requirements, and analysis methods together before data collection begins [61].
- Keep Raw Data Separate: Always save and backup the raw, unprocessed data in multiple locations and do not perform any operations on this primary file [61].
- Use Open File Formats: Save data in accessible, general-purpose file formats (e.g., CSV) to ensure long-term accessibility [61].
Quantitative Data on Common Data Issues
The table below summarizes real-world error rates and performance data related to data integrity issues.
| Issue Context | Error Rate / Performance Metric | Source / Method of Identification |
|---|---|---|
| Manual TNM Classification in Cancer Registry | 5.5% - 17.0% error rate in pathological T classification [60]. | Discrepancy analysis between registry entries and ground truth from original pathology reports [60]. |
| Internal Registry Inconsistency (Radiology vs. Clinical N) | 3.3% internal inconsistency rate [60]. | Automated logic checks comparing related data fields within the same registry [60]. |
| LLM-based Data Extraction from Text | 99.3% - 99.4% accuracy for extracting pathological T and N classifications [60]. | Application of off-the-shelf LLMs (Gemini 1.5) using prompt engineering on unstructured clinical text [60]. |
| False-Positive PMDD Diagnosis | Retrospective recall can lead to false-positive rates as high as 60% [59]. | Mandating prospective daily symptom ratings over two cycles, as per DSM-5-TR [59]. |
The Scientist's Toolkit: Research Reagent Solutions
The following table details key materials and tools for ensuring data integrity in experimental research.
| Item / Reagent | Function in Maintaining Data Integrity |
|---|---|
| Electronic Data Capture (EDC) System | Securely collects, stores, and manages data with built-in validation checks, audit trails, and access controls, reducing human error [58]. |
| Validated Computer Systems | Computer System Validation (CSQ) ensures systems operate correctly and produce reliable, reproducible results, which is a regulatory requirement [56]. |
| Prospective Daily Symptom Tool (e.g., DRSP) | Critical for PMDD research to avoid false positives from retrospective recall; provides objective, time-series data as mandated by DSM-5-TR [59]. |
| Data Dictionary | A central document that defines all variables, codes, and units, ensuring consistency and interpretability across the research team and over time [61]. |
| Large Language Models (LLMs) | Can be deployed to automatically and accurately extract structured data (e.g., classifications) from unstructured text (e.g., clinical notes), reducing manual entry errors [60]. |
| Open File Formats (e.g., CSV) | Using general-purpose, non-proprietary file formats ensures long-term accessibility and readability of data across different computing systems and software [61]. |
Experimental Workflow for Robust Data Collection
The diagram below outlines a diagnostic and correction workflow for common data integrity issues.
Data Integrity Defense Framework
This diagram visualizes the multi-layered framework for preventing data integrity issues, based on the ALCOA+ principles and robust data management.
Strategies for Differentiating Premenstrual Disorders from Premenstrual Worsening of Other Conditions
Diagnostic Criteria and Clinical Presentation
What are the core diagnostic features that differentiate a premenstrual disorder from premenstrual exacerbation?
The fundamental distinction lies in the timing and persistence of symptoms. Premenstrual Dysphoric Disorder (PMDD) is characterized by symptoms that occur exclusively during the luteal phase (the one to two weeks before menstruation), resolve shortly after menstruation begins, and are absent during the symptom-free week after menses [62] [63]. In contrast, Premenstrual Exacerbation (PME) refers to the worsening of symptoms of an underlying, persistent condition—such as major depressive disorder, anxiety disorder, or other medical conditions—during the premenstrual phase [63].
Key Differential Diagnostic Features:
| Feature | Premenstrual Dysphoric Disorder (PMDD) | Premenstrual Exacerbation (PME) |
|---|---|---|
| Symptom Timing | Symptoms are present only in the luteal phase and remit post-menses [62] [64]. | Symptoms of the primary condition are present throughout the cycle but worsen premenstrually [63]. |
| Symptom-Free Interval | A clear, symptom-free week occurs after menstruation and before ovulation [63]. | No true symptom-free interval; baseline symptoms persist across the cycle [63]. |
| Response to Ovarian Suppression | Symptoms resolve when ovarian cycling is suppressed [65] [63]. | Symptoms of the primary condition persist despite ovarian suppression [63]. |
| Primary Condition | PMDD is the primary diagnosis in the absence of other active mood disorders [62]. | Another chronic psychiatric or medical condition is the primary diagnosis [63]. |
An estimated 40% of women seeking treatment for presumed PMDD are found to have PME of an underlying mood disorder instead [63].
Assessment and Diagnostic Protocols
What is the gold-standard methodology for confirming PMDD and ruling out PME in a clinical research setting?
Prospective daily symptom charting over at least two symptomatic menstrual cycles is the mandatory gold standard for confirming PMDD and differentiating it from PME [62] [63]. Retrospective self-reporting is unreliable and can lead to a false-positive rate as high as 60% [66].
Recommended Prospective Data Collection Instruments:
| Instrument Name | Key Function/Advantage | Implementation in Research |
|---|---|---|
| Daily Record of Severity of Problems (DRSP) | A validated and reliable tool for daily tracking of the timing and severity of emotional, behavioral, and physical symptoms [65]. | Highly recommended in the DSM-5-TR for confirming PMDD diagnosis [66]. |
| Premenstrual Symptoms Screening Tool (PSST) | A recall-based screening tool useful for initial identification of individuals likely to have PMDD [10]. | Cross-sectional assessment provides a provisional PMDD diagnosis only; must be confirmed with prospective charting [10]. |
Experimental Protocol for Prospective Daily Charting
Objective: To objectively confirm the cyclical nature of symptoms and establish a diagnosis of PMDD versus PME.
Materials:
- Validated daily charting tool (e.g., DRSP).
- Calendar for tracking menstrual cycle days.
Methodology:
- Participants record the severity of specific symptoms (e.g., mood swings, irritability, depression, bloating) each evening for a minimum of two consecutive menstrual cycles [62] [63].
- The onset and end of menstruation must be marked to define the luteal and follicular phases clearly.
- Data analysis involves comparing the average symptom severity in the luteal phase (final 7 days before menses) with the severity in the follicular phase (first 7 days after menses) [62].
- A diagnosis of PMDD requires a demonstrable, significant increase in symptom severity during the luteal phase, which remits in the follicular phase [62]. If significant symptoms persist throughout the follicular phase, a diagnosis of PME is more likely.
Comorbidities and Differential Diagnosis
Which comorbid conditions most commonly complicate the differential diagnosis?
Several psychiatric and medical conditions can present with symptoms that overlap with PMDD or exhibit premenstrual exacerbation, making differential diagnosis critical.
Common Comorbidities and Differential Diagnoses:
| Condition Type | Examples | Key Differentiating Factors from PMDD |
|---|---|---|
| Psychiatric Disorders | Major Depressive Disorder, Generalized Anxiety Disorder, Bipolar Disorder, Dysthymia [67] [63]. | Symptoms are persistent and not confined to the luteal phase. PMDD resolves during pregnancy and after menopause, while other mood disorders typically persist [63]. |
| Medical Conditions | Migraines, Anemia, Thyroid Disease, Endometriosis, Irritable Bowel Syndrome, Chronic Fatigue Syndrome [67]. | Symptoms may be cyclical but are often linked to other triggers. Diagnosis is confirmed through specific medical tests (e.g., TSH for thyroid). |
| Other Premenstrual Disorders | Premenstrual Syndrome (PMS) [67]. | PMS involves at least one physical and one emotional symptom, while PMDD requires at least five symptoms of greater severity, including a core mood symptom, causing significant functional impairment [62] [67]. |
Recent research also indicates a strong association between ADHD and PMDD. One study found the prevalence of provisional PMDD was elevated to 41.1% among individuals with ADHD symptoms, compared to 9.8% in a non-ADHD reference group [10]. This highlights the importance of screening for underlying ADHD when assessing premenstrual complaints.
The Scientist's Toolkit: Research Reagent Solutions
Essential materials and tools for conducting rigorous research on premenstrual disorders.
| Research Reagent / Tool | Function / Application |
|---|---|
| Validated Prospective Symptom Trackers (DRSP) | The primary tool for confirming diagnosis and quantifying symptom severity in clinical trials [65]. |
| Structured Clinical Interviews (e.g., SCID-5) | To reliably identify and rule out comorbid psychiatric disorders that could confound diagnosis (e.g., major depression) [63]. |
| GnRH Agonists (e.g., Leuprolide) | Used experimentally to induce temporary ovarian suppression. Resolution of symptoms supports a PMDD diagnosis; persistence suggests PME [65] [63]. |
| Selective Serotonin Reuptake Inhibitors (SSRIs) | First-line pharmacologic treatment for PMDD. Their rapid efficacy (within days) when dosed intermittently in the luteal phase is a unique characteristic of PMDD and can also serve as a diagnostic probe [65] [67]. |
| Hormone Assays | Measuring serum levels of estradiol, progesterone, and allopregnanolone to correlate symptom severity with hormonal fluctuations, though absolute levels are typically normal in PMDD [62] [66]. |
Pathophysiological Insights and Biomarker Research
What are the current leading pathophysiological theories that inform the differentiation of PMDD?
While the exact etiology of PMDD is unknown, current evidence suggests it is not caused by abnormal hormone levels, but rather by an abnormal neurobiological sensitivity to normal cyclical hormonal changes [62] [63].
Key Pathophysiological Mechanisms Under Investigation:
| Mechanism | Hypothesized Role in PMDD | Research Implications |
|---|---|---|
| Sensitivity to Neuroactive Steroids | Abnormal CNS response to metabolites of progesterone (e.g., allopregnanolone) and fluctuations in estradiol, which affect GABA-A and serotonin receptor function [62] [68] [63]. | Investigate biomarkers like cerebellar activity via fMRI [68]. Drug development targeting allopregnanolone (e.g., Sepranolone) [65]. |
| Serotonergic Dysregulation | Women with PMDD show atypical serotonergic transmission, including reduced transporter receptor density [62] [59]. This explains the rapid efficacy of SSRIs [62] [65]. | SSRIs are a first-line treatment and their response can be a diagnostic indicator. |
| Genetic Vulnerability | Twin studies suggest heritable factors. Allelic variants of the estrogen receptor alpha gene (ESR1) and serotonergic genes are under investigation [62]. | Research focuses on identifying genetic markers for susceptibility. |
Frequently Asked Questions (FAQs)
Why is retrospective recall insufficient for diagnosing premenstrual disorders?
Retrospective recall is highly prone to bias. Individuals tend to over-attribute negative mood states to the premenstrual phase, leading to a high false-positive rate. One review notes that diagnoses based on retrospective recall can have a false-positive rate as high as 60% [66]. Prospective daily charting eliminates this recall bias by capturing data in real-time.
How can researchers control for comorbid psychiatric conditions in PMDD studies?
The most robust method is to use a two-stage screening process:
- Use structured clinical interviews (e.g., SCID-5) to identify and exclude individuals with active major psychiatric disorders.
- Require all eligible participants to complete prospective daily charting for a minimum of two cycles to confirm the cyclical pattern of symptoms unique to PMDD and rule out PME [63].
What are the key considerations for designing drug trials for PMDD?
- Patient Selection: Strictly use prospective confirmation of PMDD diagnosis to ensure a homogeneous study population.
- Dosing Regimens: Consider testing luteal-phase dosing of SSRIs, which is uniquely effective in PMDD and helps distinguish it from major depression, which requires continuous dosing [65] [67].
- Outcome Measures: Use validated, prospective daily measures like the DRSP as the primary endpoint [65].
- Control for Hormonal Status: Account for factors that suppress ovarian cycling (e.g., certain contraceptives, pregnancy, lactation) as they can confound results.
Establishing Data Credibility: Cross-Validation, Comparability, and Biomarker Correlates
In the study of cyclical conditions, such as premenstrual disorders, the method of data collection is paramount. A significant body of evidence indicates that retrospective self-reporting—where participants recall symptoms from memory—has poor validity and is biased toward false positives [18]. This bias is often influenced by a participant's existing beliefs about premenstrual syndrome rather than the objective, cyclical nature of their symptoms [18]. In contrast, prospective daily ratings—where participants record symptoms each day—are considered the gold standard for diagnosing conditions like premenstrual dysphoric disorder (PMDD), as they allow researchers to reliably distinguish between cyclical and non-cyclical symptoms [18] [2].
The principles of cross-validation, well-established in bioanalytical research, offer a framework for improving the accuracy and reliability of this kind of scientific measurement. This technical support center applies these rigorous principles to the challenge of reducing false positive retrospective reports in premenstrual research.
Core Principles & Definitions
What is Cross-Validation?
In regulated bioanalysis, cross-validation is a process used to demonstrate that two or more bioanalytical methods or laboratories produce comparable data [69]. It is a critical requirement when combining data from different sites in global clinical trials to ensure that all results are reliable and can be compared directly [69] [70].
Why is it Necessary?
Cross-validation is essential when:
- Different methods or laboratories are used within the same clinical program.
- Data from multiple studies are to be pooled for regulatory submission.
- A method is transferred from one laboratory to another [70].
The goal is to ensure data comparability, a principle that is directly transferable to ensuring that different methods of symptom assessment (e.g., retrospective recall vs. prospective daily tracking) yield comparable and accurate results, thereby minimizing measurement error and false positives [69].
Experimental Protocols for Cross-Validation
Protocol 1: Inter-Laboratory Cross-Validation of Bioanalytical Methods
This protocol, derived from a global study of the drug lenvatinib, outlines the steps to ensure different laboratories can produce comparable results [69].
- Objective: To confirm that multiple bioanalytical laboratories can generate comparable concentration data for a given analyte, enabling the comparison of pharmacokinetic parameters across global clinical trials.
- Method Summary:
- Method Development & Validation: Each laboratory first independently develops and fully validates its own bioanalytical method (e.g., using LC-MS/MS) according to regulatory guidelines. Parameters assessed include accuracy, precision, selectivity, and stability [69] [70].
- Cross-Validation Study: A central laboratory prepares and distributes blinded Quality Control (QC) samples with known concentrations and blinded clinical study samples with unknown concentrations to all participating laboratories.
- Sample Analysis: Each laboratory assays the blinded QC and clinical samples using their own validated method.
- Data Comparison: The results from all laboratories are statistically compared. Acceptance criteria for QC samples are typically within ±15% of the nominal concentration, while the percentage bias for clinical samples should also be within a pre-defined range (e.g., ±15%) [69].
- Key Materials:
- Calibration standards
- Quality Control (QC) samples at low, mid, and high concentrations
- Blinded clinical study samples
- Stable isotope-labeled internal standards [69]
Protocol 2: Cross-Validation of Retrospective and Prospective Symptom Assessments
This protocol adapts the bioanalytical principle to clinical symptom research, directly addressing the user's thesis on reducing false positives in premenstrual reports [71].
- Objective: To quantify the discrepancy between retrospective symptom recall and prospectively recorded daily symptoms, thereby validating a less burdensome assessment method against the gold standard.
- Method Summary:
- Retrospective Assessment: Participants complete a retrospective questionnaire (e.g., the Menstrual Distress Questionnaire - MDQ) at the start of the study, recalling the severity and frequency of symptoms they typically experience premenstrually [71].
- Prospective Daily Assessment (Gold Standard): Immediately after, participants complete a daily symptom diary (e.g., the Daily Record of Severity of Problems - DRSP) for one or more full menstrual cycles. The recall period for items is modified to "In the last day..." [28] [4].
- Data Aggregation & Scoring: Prospective daily scores are aggregated to create an average symptom score for the premenstrual (late-luteal) phase.
- Statistical Cross-Validation: Retrospective scores are statistically compared to the aggregated prospective scores using correlation analyses (e.g., Pearson's r) and tests of mean differences (e.g., paired t-tests). A high correlation supports the ecological validity of the retrospective tool, while a significant mean difference often indicates overestimation in retrospective recall [28] [71].
The following workflow illustrates this cross-validation process for clinical symptoms.
Troubleshooting Guides
Problem: Poor Correlation Between Prospective and Retrospective Data
- Potential Cause 1: High Recall Bias.
- Solution: The retrospective tool may not be valid. Use shorter recall periods or consider abandoning the retrospective tool in favor of the prospective gold standard. Research shows retrospective total scores are often significantly higher than prospective scores, indicating overestimation [71].
- Potential Cause 2: Non-Cyclical Symptoms Confounding Data.
Problem: High Participant Burden in Prospective Daily Tracking
- Potential Cause: Daily reporting leads to fatigue and non-compliance.
- Solution: Validate and implement a weekly Computerized Adaptive Testing (CAT) system. PROMIS CAT instruments for anger, depression, and fatigue have demonstrated high ecological validity (correlations with daily scores ranging from .73 to .88) and can accurately detect cyclical symptom changes with far fewer items, reducing participant burden [28].
Problem: Inconsistent Results Across Different Research Sites
- Potential Cause: Lack of standardized methods and cross-validation.
- Solution: Implement a formal cross-validation protocol between sites, mirroring bioanalytical practices. Ensure all sites use the same assessment tools, scoring algorithms, and standard operating procedures. Analyze a common set of "reference" symptom data to quantify and correct for inter-site variability [69].
Frequently Asked Questions (FAQs)
Q1: Why can't we just use retrospective reports? They are faster and cheaper. A1: Retrospective self-report assessment has poor validity and is biased toward false positives because it is heavily influenced by a participant's beliefs about premenstrual syndrome [18]. Studies show that women can accurately recall their major symptoms but tend to retrospectively overestimate the severity compared to prospective assessment [71]. This inflates prevalence rates and confounds research.
Q2: What is the minimum number of cycles required for prospective diagnosis? A2: DSM-5 guidelines require prospective daily symptom ratings for at least two symptomatic cycles to confirm the cyclical pattern and establish a reliable diagnosis of PMDD [18] [2].
Q3: How does bioanalytical cross-validation relate to clinical symptom research? A3: The core principle is the same: establishing data comparability. In bioanalysis, it ensures lab results are comparable across sites. In clinical research, it ensures that a less burdensome assessment tool (e.g., a weekly survey) yields data that is comparable to the gold standard (daily diaries), thereby reducing error and false positives without sacrificing scientific rigor [28] [69].
Q4: Are there objective measures to complement self-reported symptoms? A4: Yes, emerging research uses tools like Near-Infrared Spectroscopy (NIRS) to measure objective biomarkers like brain activity in the prefrontal cortex during cognitive tasks. Studies have shown significantly lower brain activation during the luteal phase in women with PMS compared to those without, providing a potential objective validator for the condition [72].
The Scientist's Toolkit: Essential Research Reagents & Materials
Table 1: Key tools and materials for cross-validation in clinical and bioanalytical research.
| Item | Function & Application |
|---|---|
| Daily Record of Severity ofProblems (DRSP) | The gold-standard prospective daily diary for tracking premenstrual symptoms. Used to confirm the cyclical nature and severity of symptoms as required by DSM-5 [2] [4]. |
| PROMIS CAT Instruments | Computerized Adaptive Testing (CAT) for anger, depression, and fatigue. Provides a precise, brief (4-12 items) weekly assessment that has been cross-validated against daily diaries [28]. |
| Carolina PremenstrualAssessment Scoring System (C-PASS) | A standardized, computerized scoring system that applies DSM-5 criteria to prospective daily data (e.g., from the DRSP) to diagnose PMDD and distinguish it from premenstrual exacerbations of other disorders [18] [4]. |
| Quality Control (QC) Samples | In bioanalysis, these are samples with known analyte concentrations. They are crucial for cross-validation, as they are assayed by all laboratories to confirm the accuracy and comparability of their methods [69]. |
| Stable Isotope-LabeledInternal Standard | A critical reagent in LC-MS/MS bioanalysis (e.g., 13C6-lenvatinib). It corrects for variability in sample preparation and ionization, improving accuracy and precision—a key factor in successful cross-validation [69]. |
Data Presentation: Quantitative Evidence
The following tables summarize key quantitative findings from the search results that support the principles discussed.
Table 2: Comparison of retrospective and prospective symptom assessment scores (n=55). Adapted from [71].
| Assessment Method | Mean MDQ Total Score | Statistical Significance | Note |
|---|---|---|---|
| Retrospective Recall | Significantly Higher | p < 0.001 | Average overestimation of 23.7% ± 35.0% |
| Prospective Late-Luteal | Significantly Lower | (Baseline for comparison) | Considered a more accurate baseline |
Table 3: Correlation between weekly PROMIS CAT scores and aggregated daily scores. Data from [28].
| Symptom Domain | Correlation with Daily Scores | Conclusion |
|---|---|---|
| Anger | .73 to .88 | Supports ecological validity of the weekly CAT tool |
| Depression | .73 to .88 | Supports ecological validity of the weekly CAT tool |
| Fatigue | .73 to .88 | Supports ecological validity of the weekly CAT tool |
Table 4: Key parameters from an inter-laboratory bioanalytical cross-validation study for lenvatinib. Data from [69].
| Parameter | Result | Acceptance Criteria |
|---|---|---|
| Accuracy of QC Samples | Within ±15.3% | Typically within ±15% |
| Bias for Clinical Samples | Within ±11.6% | Typically within ±15% |
Establishing Comparability Between Different Methodologies and Sites
This technical support center provides troubleshooting guides and FAQs for researchers working to establish comparability between different methodologies and sites, specifically within the context of reducing false positive retrospective premenstrual reports.
Frequently Asked Questions (FAQs)
Q1: What does "establishing comparability" mean in the context of multi-site hormone research? Establishing comparability is the process of ascertaining whether different assessment methods used across research sites provide substantially the same outcomes [73]. In hormonal research, this ensures that data on premenstrual symptoms collected retrospectively via different questionnaires or across different clinical sites are equivalent and can be reliably pooled or compared.
Q2: My study sites are using different versions of the Menstrual Distress Questionnaire (MDQ). How can I ensure data comparability? You should develop and agree upon a set of high-level principles and final comparability criteria before data collection begins [73]. A robust process includes:
- Using a standardized definition of comparable outcomes across all sites.
- Establishing a pre-defined set of principles to guide the development of detailed comparability criteria.
- Finalizing these criteria through a transparent process before the assessment begins.
Q3: We are seeing high variability in retrospective symptom reports between our sites. What could be the cause? High background "noise" in data can stem from several factors analogous to insufficient washing in an assay, which leaves behind unbound material [74]. Potential sources include:
- Inconsistent Participant Instruction: Variations in how the questionnaire is explained to participants across sites.
- Procedural Error: Differences in data collection environments (e.g., clinical setting vs. online at home).
- Cultural or Linguistic Factors: For studies in multiple languages or countries, subtle differences in translation or cultural interpretation of symptoms can introduce error.
Q4: What should I do if one research site reports unexpectedly low severity scores for all symptoms? This is similar to a "no signal when a signal is expected" scenario in experimental protocols [74]. The troubleshooting steps include:
- Repeat the assessment: The site may have made a simple procedural error.
- Check calculations and make new buffers/standards: Verify the data entry process and scoring algorithms for errors.
- Review the protocol: Ensure the site adhered to the exact study protocol and used the correct version of the assessment tool.
- Requalify your reagents: Confirm that the site used the validated and approved questionnaire.
Q5: How can I improve poor duplication (high variability) in symptom scores within the same participant group? Poor duplicates often stem from inconsistent procedures [74]. To address this:
- Ensure sufficient washing/standardization: Implement strict, uniform training for all research staff across sites.
- Check for uneven coating/ procedural error: Audit each site's data collection process for deviations from the protocol.
- Avoid reusing plate sealers/contamination: Use fresh, unique participant IDs and ensure data is entered into a clean database.
- Use fresh buffers: Standardize the statistical software and analysis scripts used by all sites.
Troubleshooting Guides
Guide 1: Troubleshooting Poor Inter-Site Data Comparability
Problem: Data collected from different research sites shows significant statistical variability, making it unreliable to pool results.
| Possible Source | Test or Action |
|---|---|
| Variations in protocol execution | Adhere to the same protocol from run to run; implement a mandatory, standardized training program for all site staff [74]. |
| Inconsistent data entry or management | Use a centralized electronic data capture (EDC) system with built-in validation checks to reduce human error. |
| Demographic or cultural differences in cohort | Pre-define strict, consistent eligibility criteria and use stratified randomization. Report cohort demographics in detail [39]. |
| Improper calculation of symptom scores | Check calculations; use automated, pre-programmed scoring within the EDC system to ensure consistency [74]. |
Guide 2: Troubleshooting Recall Bias in Retrospective Reports
Problem: Retrospective self-reports of premenstrual symptoms may be exaggerated or minimized, leading to false positives or negatives.
| Possible Source | Test or Action |
|---|---|
| Global retrospective recall | Supplement with prospective daily symptom tracking to provide a more accurate baseline and mitigate the influence of current state on memory [39]. |
| Lack of anchoring in daily experience | Use validated tools like the Menstrual Cycle-Related Work Productivity Questionnaire, which ties symptoms to concrete functional impacts like concentration and mood at work [39]. |
| Symptom masking by sample matrix | Dilute samples/run controls; in analysis, statistically control for potential confounding variables like age, BMI, and contraceptive use reported in the demographic data [39] [74]. |
Table 1: Hormonal Symptom Prevalence and Impact on Work Productivity
| Metric | Value | Notes |
|---|---|---|
| Working females of reproductive age in the U.S. | Nearly 60 million | Represents the scale of the potential population under study [39]. |
| Females reporting missed work due to their menstrual cycle (past year) | 45.2% | Indicates a significant impact of symptoms on absenteeism [39]. |
| Average days of work missed | 5.8 days | Quantifies the burden of absenteeism [39]. |
| Contribution of presenteeism to productivity loss | Larger than absenteeism | Highlights that working while symptomatic is a major factor in productivity loss [39]. |
Table 2: WCAG 2.1 Color Contrast Requirements for Data Visualization
This table defines the minimum contrast ratios for creating accessible diagrams and charts, ensuring information is perceivable by all researchers [75].
| Element Type | WCAG Level | Minimum Contrast Ratio | Notes |
|---|---|---|---|
| Normal Text (images of text, labels) | AA | 4.5:1 | Applies to most text in diagrams [75]. |
| Large Text (18pt+ or 14pt+ bold) | AA | 3:1 | Applies to large headings or labels [75]. |
| User Interface Components & Graphical Objects | AA (WCAG 2.1) | 3:1 | Applies to chart elements, icons, and buttons [75]. |
| Normal Text | AAA | 7:1 | Enhanced requirement for higher accessibility [75]. |
| Large Text | AAA | 4.5:1 | Enhanced requirement for higher accessibility [75]. |
Experimental Protocols
Protocol 1: Implementing a Multi-Method Symptom Assessment Strategy
Purpose: To reduce false positive retrospective reports by combining retrospective and prospective data collection methods.
Baseline Retrospective Assessment:
- Tool: Administer the validated Menstrual Distress Questionnaire (MDQ) [39]. The MDQ consists of 47 items rated on a five-point scale and yields eight subscale scores and a total distress score.
- Timing: Participants recall symptoms over three time frames: during the last menstrual flow (menstrual), the week prior to the last flow (premenstrual), and the remainder of the most recent menstrual cycle (intermenstrual) [39].
Prospective Daily Tracking:
- Tool: Implement a daily digital diary for one full menstrual cycle. This diary should include key items from the MDQ to ensure cross-walking of data.
- Procedure: Participants log symptom severity daily. Reminders are sent via SMS or a dedicated application to enhance compliance.
Follow-up Retrospective Assessment:
- Tool: Re-administer the MDQ at the end of the daily tracking period, asking participants to reflect on the cycle they just completed prospectively.
Data Analysis for Comparability:
- Statistically compare the prospective data with the two retrospective reports (baseline and follow-up).
- Assess the degree of alignment between the follow-up retrospective report and the prospective "gold standard." A high level of comparability indicates the retrospective tool is valid for the cohort.
- Investigate discrepancies between the baseline retrospective report and the prospective data to quantify and understand the direction of recall bias.
Protocol 2: Cross-Site Data Harmonization Protocol
Purpose: To ensure that data collected from multiple research sites is comparable and can be aggregated.
Pre-Study Harmonization:
- Define Comparability Criteria: Establish a set of high-level principles and final, detailed criteria for what constitutes comparable data outcomes between sites [73].
- Centralized Training: Conduct a single, mandatory training session for all research coordinators from all sites, using standardized materials.
Standard Operating Procedure (SOP) Implementation:
- Documentation: Provide a detailed SOP covering participant recruitment, consenting, tool administration, data entry, and query resolution.
- Equipment & Reagents: Standardize the software platforms, questionnaire versions, and any other materials used across all sites.
Ongoing Quality Control:
- Centralized Monitoring: Use a central institutional review board (IRB) and a data coordinating center to monitor protocol adherence [39].
- Blinded Re-assessment: Periodically, have a subset of participant data from each site re-assessed by a central panel to check for scoring consistency.
Research Reagent Solutions
Table 3: Essential Materials for Hormonal Symptom Comparability Research
| Item | Function in Research |
|---|---|
| Menstrual Distress Questionnaire (MDQ) | A validated tool for measuring the presence and intensity of cyclical menstrual symptoms retrospectively. It provides a standardized metric for cross-site comparison [39]. |
| Menstrual Cycle-Related Work Productivity Questionnaire | A modified questionnaire that assesses the bidirectional impact of hormonal symptoms on work-related productivity (e.g., concentration, efficiency), linking symptoms to tangible outcomes [39]. |
| Prospective Digital Symptom Diary | A tool for daily symptom tracking to establish a more accurate baseline and mitigate the limitations of retrospective recall, serving as a comparator for retrospective tools. |
| Centralized Electronic Data Capture (EDC) System | A unified software platform for data entry across all sites. It reduces manual errors, ensures data is stored consistently, and facilitates real-time data quality checks. |
| Demographic & Covariate Questionnaire | A standardized form to collect information on age, BMI, contraceptive use, and heavy bleeding experience. This data is essential for controlling potential confounders in statistical analysis [39]. |
Experimental Workflow and Signaling Pathways
Hormonal Symptom Research Workflow
Multi-Site Data Harmonization Logic
Symptom Impact Analysis Pathway
Correlating Prospective Symptom Data with Putative Biomarkers
FAQs: Addressing Core Methodological Challenges
Q1: How can I minimize recall bias when studying cyclical symptoms like PMS? Retrospective symptom reports are highly susceptible to recall bias, where participants' recollections are influenced by their expectations or most recent severe experience [76]. To counter this, implement prospective daily tracking for at least one to two menstrual cycles [72] [77]. Use validated, granular tools like the Daily Record of Severity of Problems (DRSP) or implement a daily version of the Menstrual Distress Questionnaire (MDQ) Form T [77]. This method captures symptoms as they occur, providing a more accurate picture than retrospective recall.
Q2: What is the best way to define the luteal phase for biomarker correlation in individuals with irregular cycles? In peripubertal, perimenopausal, or clinically irregular cycles, calendar-based phase estimation is unreliable [78]. Instead, use objective, prospective hormonal criteria:
- Urinary Biomarkers: Collect daily dried urine samples to track metabolites of estrogen (E1G) and progesterone (PdG), and Luteinizing Hormone (LH) [78].
- Ovulation Detection: Apply validated algorithms (e.g., Sun et al., Park et al.) to the urinary hormone data to confirm ovulation and identify the post-ovulatory luteal phase accurately [78].
- Phase Definition: Define the luteal phase from the day after the LH peak until the day before menses onset, ensuring biomarker-symptom correlations are aligned with correct neuroendocrine phases [78].
Q3: Beyond blood, what other biomarker sources are useful for psychiatric or neurological symptom correlation? Biomarkers can be derived from multiple sources, each offering unique insights [79] [80]:
- Neurophysiological Signals: Electroencephalography (EEG) can measure biomarkers like Mismatch Negativity (MMN), which reflects early auditory processing and is a robust, translatable biomarker for conditions like psychosis [81].
- Neuroimaging: Functional Near-Infrared Spectroscopy (fNIRS) can assess cognitive function by measuring prefrontal cortex activity during tasks, revealing phase-dependent changes in brain activation in PMS [72].
- Genomic and Molecular Tools: Polygenic risk scores, epigenetic clocks (e.g., for allostatic load), and microbiome analyses can provide deeper biological context for symptom susceptibility [79].
Q4: How can I validate that a putative biomarker has a clinically meaningful relationship with a symptom? A robust validation strategy involves several steps:
- Repeated Measures: Collect the biomarker and symptom data at multiple time points across the cycle or disease course to establish a temporal relationship [78] [72].
- Statistical Rigor: Use mixed-effects models to account for within-subject correlations. Correct for multiple comparisons (e.g., Bonferroni, FDR) when testing multiple biomarkers [82].
- Functional Correlation: The biomarker should correlate not just with symptom severity but also with functional outcomes. For example, in psychosis, MMN deficits are correlated with impaired psychosocial functioning and community independence [81].
Troubleshooting Guides
Issue: High Participant Burden in Prospective Data Collection
Problem: Daily symptom and biomarker sampling leads to participant fatigue and poor protocol adherence. Solution: Implement a tiered and technology-facilitated approach:
- Use Feasible Methods: For hormones, utilize home-collection kits for dried urine or saliva, which are less invasive than blood draws [78].
- Leverage Digital Tools: Employ mobile health apps for daily symptom logging and reminders, which can improve compliance.
- Strategic Sampling: Instead of daily sampling for an entire cycle, use a "hormone sampling trigger" design. Begin daily sampling only after a participant reports a predefined increase in symptom severity.
Issue: Inconsistent or No Correlation Between Biomarker and Symptom Trajectories
Problem: The hypothesized biomarker does not align with symptom reports in the prospective dataset. Solution: Systematically check for these potential confounders:
- Verify Phenotyping: Re-examine your symptom phenotyping. Are you studying a homogeneous group (e.g., PMDD only) or a mixed group? Use strict diagnostic criteria (e.g., PSST for PMDD) to create more biologically homogeneous subgroups [77].
- Check for Lagged Effects: The relationship may not be concurrent. Explore time-lagged correlations (e.g., does a hormone level on day X predict symptoms on day X+1 or X+2?).
- Consider Biomarker Panels: Single biomarkers rarely tell the whole story. Investigate ratios or interactions between biomarkers (e.g., estrogen-to-progesterone ratio, allostatic load index) which may be more predictive than any single marker [79].
- Control for Covariates: Ensure statistical models include relevant covariates like sleep, stress, and medication use, which can influence both biomarkers and symptoms.
Issue: Integrating Biomarker Data with Real-World or Electronic Health Record (EHR) Data
Problem: Leveraging large EHR populations for biomarker discovery is difficult because the biomarkers of interest are not routinely measured. Solution: Employ a genetically-informed biomarker imputation paradigm [82]:
- Develop a Genetic Predictor: In a deeply phenotyped cohort (e.g., ARIC study), use methods like Bayesian sparse linear mixed modeling (BSLMM) to develop a genetic score that predicts levels of your biomarker [82].
- Impute into EHR Cohort: Calculate this genetically-predicted biomarker level for individuals in a large, genotyped EHR database (e.g., eMERGE network).
- Conduct Phenome-Wide Association Study (PheWAS): Test for associations between the imputed biomarker and a wide range of clinical diagnoses to map the biomarker's clinical epidemiology efficiently [82]. Table: Advantages of the Genetic Imputation Approach for Biomarker Discovery
| Advantage | Description |
|---|---|
| Scalability | Allows for the study of biomarker-disease associations in very large populations without the cost of direct biomarker measurement [82]. |
| Efficiency | Rapidly defines the full spectrum of clinical phenotypes associated with a biomarker [82]. |
| Discovery Power | Can reveal novel, unsuspected associations between a biomarker and diseases, generating new hypotheses [83]. |
Experimental Protocols & Data Presentation
Protocol 1: Prospective Urinary Hormone and Symptom Correlation
Objective: To correlate daily fluctuations in ovarian hormones with prospective mood and physical symptoms in the menstrual cycle.
Materials:
- Hormone Kit: Dried urine spot cards for home collection, LC-MS/MS for analysis of E1G and PdG metabolites [78].
- Symptom Tool: Validated daily questionnaire (e.g., DRSP or customized MDQ Form T) [77].
- Ovulation Confirmation: Luteinizing Hormone (LH) test strips or urinary LH via assay [78].
Methodology:
- Participant Training: Train participants to complete daily symptom reports and collect first-morning urine samples.
- Duration: Data collection for one complete menstrual cycle (or up to 48 days to capture long cycles) [78].
- Ovulation & Phase Definition:
- Identify the LH peak in the urine data.
- Apply a validated algorithm (e.g., Sun et al. 2019) to identify the PdG rise and confirm ovulation [78].
- Define cycle phases: Follicular (menses to LH peak), Luteal (day after LH peak to day before next menses).
- Data Analysis:
- Synchronize hormone and symptom data by cycle day and phase.
- Use linear mixed-models to test for associations between hormone levels (E1G, PdG) and symptom severity, with participant as a random effect.
Protocol 2: Using fNIRS as an Objective Biomarker for Cognitive Symptoms in PMS
Objective: To objectively assess cognitive function changes across the menstrual cycle using functional Near-Infrared Spectroscopy (fNIRS) [72].
Materials:
- fNIRS System: A portable fNIRS device with channels covering the prefrontal cortex.
- Cognitive Task: N-back task (0-, 1-, and 2-back) to assess working memory [72].
- Symptom Assessment: Premenstrual Symptoms Screening Tool (PSST) to classify participants into PMS and control groups [77].
Methodology:
- Group Allocation: Recruit females with PMS and matched controls, confirmed via PSST.
- Testing Sessions: Schedule fNIRS testing during the mid-follicular phase (cycle days 5-10) and the mid-luteal phase (cycle days 19-24), confirmed by ovulation testing [72].
- Procedure: During fNIRS scanning, participants complete the N-back task. The primary outcome is the change in oxy-hemoglobin concentration in the prefrontal cortex.
- Data Analysis:
- Compare the correct response rate and brain activation (oxy-Hb integral value) between groups (PMS vs. control) and within groups (follicular vs. luteal phase) using repeated-measures ANOVA [72].
Table: Key Symptom and Biomarker Assessment Tools
| Tool / Assay | Function | Application Context |
|---|---|---|
| Premenstrual Symptoms Screening Tool (PSST) | Screens for PMDD and PMS severity; assesses 14 symptoms & 5 functional items [77]. | Participant screening and group stratification. |
| Menstrual Distress Questionnaire (MDQ) Form T | Daily self-report of physical, behavioral, and emotional symptoms [77]. | Prospective daily symptom tracking. |
| Dried Urine Spot Testing | Home collection of urine for LC-MS/MS analysis of E1G, PdG, and LH [78]. | Prospective, at-home hormone metabolite sampling. |
| fNIRS with N-back Task | Measures prefrontal cortex activity (oxy-Hb) during a working memory task [72]. | Objective biomarker for cognitive function changes. |
| Mismatch Negativity (MMN) EEG | An EEG paradigm that measures pre-attentive auditory sensory memory [81]. | Translational biomarker for psychosis risk and cognitive deficits. |
The Scientist's Toolkit: Research Reagent Solutions
Table: Essential Materials for Biomarker and Symptom Correlation Studies
| Item | Function | Example Use Case |
|---|---|---|
| Dried Urine Spot Cards | Stable, room-temperature transport of urine samples for hormone analysis [78]. | Home-based collection of estrogen and progesterone metabolites for cycle phase confirmation [78]. |
| High-Sensitivity Immunoassays / LC-MS/MS | Precise quantification of low-concentration biomarkers (hormones, CRP, etc.) in blood, urine, or saliva [80]. | Measuring cortisol, estradiol, progesterone, and inflammatory markers like hs-CRP [80]. |
| Portable fNIRS System | Non-invasive functional brain imaging that measures cortical blood flow during cognitive tasks [72]. | Objectively quantifying prefrontal cortex dysfunction during the luteal phase in PMS [72]. |
| EEG System with MMN Paradigm | Records electrical brain activity to assess auditory sensory memory and neuroplasticity [81]. | Predicting conversion to psychosis in high-risk individuals or assessing cognitive training response [81]. |
| Validated Digital Symptom Tracker | Mobile app or web platform for real-time, prospective symptom logging. | Reducing recall bias by collecting symptom data daily in the participant's natural environment [77]. |
| Polygenic Risk Score (PRS) Algorithms | Computational tools to calculate an individual's genetic susceptibility to a trait or disease [79] [82]. | Stratifying patients by genetic risk to identify more homogeneous subgroups for biomarker analysis [82]. |
Visualized Workflows & Pathways
Diagram 1: Prospective Study Workflow for Reducing False Positives
Diagram 2: Biomarker Integration & Analytical Framework
Foundational Concepts: The False Positive Analogy
What constitutes a true false positive in disease subtyping research?
In temporal subtyping analysis, a true false positive occurs when a presumed temporal subtype is identified but does not represent a biologically or clinically distinct entity. This mirrors the concept in diagnostic testing where a positive result appears in the absence of the actual condition. Understanding this distinction is crucial for avoiding misinterpretation of temporal patterns that may arise from methodological artifacts rather than true biological differences [84].
How do temporal distribution shifts create false positive risks in retrospective analyses?
Temporal distribution shifts present significant challenges in retrospective research by introducing non-biological patterns that can be mistaken for genuine subtypes. These shifts occur when the underlying data distribution changes over time due to factors including [85]:
- Evolving diagnostic criteria and disease definitions
- Improvements in detection technologies with varying sensitivities
- Changing patient demographics and referral patterns
- Modifications in coding practices and medical record systems
These temporal artifacts can create the illusion of distinct subtypes when researchers apply homogeneous disease models to inherently heterogeneous populations, potentially leading to false conclusions about disease mechanisms and subtypes [86] [85].
Methodological Framework: Analytical Approaches
What statistical methods help distinguish true temporal subtypes from artifacts?
Advanced statistical approaches are essential for robust temporal subtyping. The table below summarizes key methodologies and their applications for addressing heterogeneity:
Table 1: Statistical Methods for Temporal Subtype Analysis
| Method | Primary Function | Application Context | Key Considerations |
|---|---|---|---|
| Relative Survival Analysis | Separates disease-specific mortality from background mortality | Population-based cancer studies | Requires matched general population data; interprets net survival [87] [88] |
| Standardization | Estimates marginal effects by creating synthetic populations with fixed characteristics | Comparing outcomes across periods with changing case mix | Provides population-averaged effects; minimizes selection bias [87] [88] |
| EM Test for Heterogeneity | Determines existence and number of patient subgroups | Predictive model development with potential latent classes | Controls false positives; sequential testing structure [86] |
| Mixture of GLMs | Models differential covariate effects across subgroups | Accounting for heterogeneous treatment or biomarker effects | Allows probabilistic subgroup assignments; reduces false discovery [86] |
How should researchers implement temporal trend analysis to minimize false findings?
Proper implementation of temporal analysis requires careful methodological planning [87] [88]:
Continuous vs. Categorical Time Modeling: Avoid arbitrary calendar period categorization which may lead to information loss. Instead, use continuous modeling with smoothers (e.g., splines) to capture non-linear temporal patterns without strong assumptions about the functional form.
Covariate Adjustment Strategy: Recognize that multivariate models provide conditional effects that may not reflect population-level patterns. Use standardization methods to estimate marginal effects that are more relevant for population health and resource planning.
Handling of Multiple Changes: Acknowledge that temporal effects represent the accumulation of all changes in clinical practice, patient characteristics, and general health over time. Disentangling specific drivers requires additional causal inference approaches beyond standard temporal trend analysis.
Troubleshooting Guide: Common Scenarios and Solutions
How can researchers resolve issues with apparent temporal subtypes that may be artifacts?
Table 2: Troubleshooting Guide for Temporal Subtype Analysis
| Problem Scenario | Potential Root Causes | Diagnostic Questions | Resolution Steps |
|---|---|---|---|
| Apparent subtype disappears after methodological adjustment | Changing patient characteristics over time; Coding or diagnostic practice shifts | Has the case-mix changed systematically? Were major diagnostic criteria updated? | Apply standardization methods; Conduct sensitivity analysis using fixed criteria [87] [88] |
| Inconsistent subtype patterns across datasets | Differential data quality over time; Institution-specific practice variations | Are data collection methods consistent? Do inclusion criteria vary by period? | Harmonize data using common data models; Validate findings across multiple sites [85] |
| Subtypes defined by single temporal cutpoints | Arbitrary period selection; Overfitting to local temporal variations | Why was this specific cutpoint chosen? Does the pattern persist with adjacent cutpoints? | Use multiple temporal groupings; Implement cross-validation; Test continuous time models [87] |
| Failure to replicate identified subtypes | Sample-specific artifacts; Inadequate adjustment for temporal confounders | Was the initial finding robust to multiple methods? Were temporal confounders fully addressed? | Pre-specify analysis plans; Use independent validation cohorts; Apply multiple subtype discovery methods [86] |
Research Reagent Solutions: Essential Methodological Tools
What key analytical components are essential for robust temporal subtype analysis?
Table 3: Essential Methodological Tools for Temporal Subtype Research
| Research Component | Function | Implementation Examples |
|---|---|---|
| General Population Data | Provides reference mortality rates for relative survival analysis | National life tables; Census mortality data; Matched reference populations [87] [88] |
| Standardization Weights | Creates synthetic populations with stable characteristics | Inverse probability weights; Direct standardization; External reference distributions [87] |
| Heterogeneity Testing Framework | Formally tests for subgroup existence before assignment | EM test for mixture models; Likelihood ratio tests; Bootstrap procedures [86] |
| Temporal Spline Terms | Flexible modeling of non-linear time effects | Restricted cubic splines; B-splines; Smoothing splines in proportional hazards models [87] [88] |
Visual Workflows: Analytical Processes and Decision Pathways
What is the complete analytical workflow for temporal subtype validation?
The diagram below illustrates the comprehensive workflow for robust temporal subtype analysis:
Frequently Asked Questions
How can we distinguish true temporal subtypes from statistical artifacts?
True temporal subtypes demonstrate consistent patterns across multiple analytical approaches, exhibit biological plausibility, and replicate in independent datasets. Statistical artifacts, in contrast, often disappear with appropriate methodological adjustments for temporal distribution shifts and show inconsistent patterns across sensitivity analyses. Implementation of formal heterogeneity testing before subgroup assignment provides protection against false discoveries [86].
What sample size considerations are important for temporal subtype detection?
Sample size requirements depend on the expected effect sizes between subtypes, the number of putative subgroups, and the complexity of the temporal patterns. Mixture model approaches generally require substantial sample sizes for stable estimation, particularly when testing multiple candidate subtypes. Statistical power for temporal trend detection increases with longer observation periods and more frequent measurements, but must be balanced against the risk of incorporating excessive temporal heterogeneity [86].
How often should temporal subtype models be updated with new data?
Temporal subtype models should be periodically re-evaluated as additional data accumulates, particularly when there are significant changes in diagnostic capabilities, treatment paradigms, or disease definitions. However, frequent re-analysis with minimal new information increases false discovery risk. Establish predefined criteria for model updates based on either temporal intervals (e.g., annually) or accumulation of substantial new data (e.g., 20% increase in sample size) [87] [85].
What are the most common pitfalls in interpreting temporal patterns as subtypes?
Common pitfalls include:
- Confounding by temporal trends in diagnostic intensity or coding practices
- Overinterpretation of single timepoint divisions without continuous modeling
- Failure to account for changing case-mix and patient characteristics over time
- Inadequate adjustment for multiple comparisons when testing multiple temporal cutpoints
- Circular reasoning where temporal patterns are used to define subtypes which are then "validated" by those same temporal patterns
Robust temporal subtyping requires pre-specified analytical plans, appropriate adjustment for temporal confounders, and validation in independent data sources [87] [86] [85].
Conclusion
Reducing false positives in premenstrual reports is not merely a methodological refinement but a foundational requirement for valid etiologic, genetic, and therapeutic research. The integration of prospective daily ratings is paramount, moving from a luxury to a necessity for generating reliable, regulatory-grade evidence. By adopting the rigorous frameworks outlined—from foundational understanding and gold-standard application to practical troubleshooting and robust validation—researchers can significantly enhance the specificity and scientific impact of their work. Future directions must focus on developing and validating scalable digital tools, exploring objective neurobehavioral and biomarker correlates to supplement self-report, and establishing standardized cross-validation protocols that meet evolving regulatory standards for real-world evidence. This rigorous approach is essential for accurately understanding disease mechanisms and developing effective interventions for premenstrual disorders.
References
- 1. Seeking to improve criterion and construct validity of ... [https://www.nature.com/articles/s41598-025-16741-8]
- 2. Diagnostic validity of premenstrual dysphoric disorder [https://www.frontiersin.org/journals/global-womens-health/articles/10.3389/fgwh.2023.1181583/full]
- 3. The prevalence of premenstrual dysphoric disorder [https://www.sciencedirect.com/science/article/pii/S0165032724000764]
- 4. Predictors of Premenstrual Impairment Among Women ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC5486218/]
- 5. Core Symptoms That Discriminate Premenstrual Syndrome [https://pmc.ncbi.nlm.nih.gov/articles/PMC3017419/]
- 6. Clarifying the causes of consistent and inconsistent ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC9544854/]
- 7. Detecting false positive signals in exome sequencing - PMC [https://pmc.ncbi.nlm.nih.gov/articles/PMC3302978/]
- 8. Evaluating solutions to the problem of false positives [https://www.sciencedirect.com/science/article/abs/pii/S0048733317302111]
- 9. Developing a Mood and Menstrual Tracking App for People ... [https://formative.jmir.org/2024/1/e59333]
- 10. Increased risk of provisional premenstrual dysphoric ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC7617793/]
- 11. Practices of Science: False Positives and False Negatives [https://manoa.hawaii.edu/exploringourfluidearth/chemical/matter/properties-matter/practices-science-false-positives-and-false-negatives]
- 12. Interpreting A/B test results: false positives and statistical ... [https://netflixtechblog.com/interpreting-a-b-test-results-false-positives-and-statistical-significance-c1522d0db27a]
- 13. Factors Affecting Recall of Different Types of Personal Genetic ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC4470386/]
- 14. Participants' recall and understanding of genomic research ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC3995160/]
- 15. Participant perspective on the recall-by-genotype research ... [https://www.nature.com/articles/s41431-022-01277-6]
- 16. Reliability of prospective and retrospective maternal reports of ... [https://bmcpregnancychildbirth.biomedcentral.com/articles/10.1186/s12884-022-05286-7]
- 17. A scoping review of the methodological approaches used in ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11086704/]
- 18. Etiologic Studies of Premenstrual Disorders Require ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11003515/]
- 19. Why are some people more susceptible to severe PMS ... [https://www.apa.org/monitor/2023/09/emerging-science-severe-pms]
- 20. 确诊经期焦虑症(PMDD):女性被激素控制的大部分人生。 [https://www.medsci.cn/article/show_article.do?id=462c88835e3e]
- 21. 精神疾病診斷與統計手冊 [https://zh.wikipedia.org/wiki/%E7%B2%BE%E7%A5%9E%E7%96%BE%E7%97%85%E8%A8%BA%E6%96%B7%E8%88%87%E7%B5%B1%E8%A8%88%E6%89%8B%E5%86%8A]
- 22. International Classification of Diseases (ICD) [https://www.who.int/standards/classifications/classification-of-diseases]
- 23. 电子健康记录(EHR)系统中用于持续学习的数据管理 [https://www.ebiotrade.com/newsf/2025-11/20251108172639634.htm]
- 24. 新版DSM 预计4 年后发布| APA2025 [https://view.inews.qq.com/a/20250604A08GWN00]
- 25. 电子病历管理:医疗信息化的核心驱动力与未来展望 - 侠医软件 [https://www.ixiayi.net/news/1398.htm]
- 26. 电子病历市场规模与未来展望2030 [https://www.mordorintelligence.com/zh-CN/industry-reports/global-electronic-medical-records-market-industry]
- 27. How to study the menstrual cycle - PubMed Central - NIH [https://pmc.ncbi.nlm.nih.gov/articles/PMC8363181/]
- 28. Ecological Validity and Clinical Utility of Patient-Reported ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC4162640/]
- 29. Within-Subjects Design | Explanation, Approaches, Examples [https://www.scribbr.com/methodology/within-subjects-design/]
- 30. Within-Subjects Design: Examples, Pros & Cons [https://www.simplypsychology.org/within-subjects-design.html]
- 31. Between-Subjects vs. Within-Subjects Study Design [https://www.nngroup.com/articles/between-within-subjects/]
- 32. Premenstrual syndrome (PMS) - Diagnosis & treatment [https://www.mayoclinic.org/diseases-conditions/premenstrual-syndrome/diagnosis-treatment/drc-20376787]
- 33. Field work I: selecting the instrument for data collection - PMC [https://pmc.ncbi.nlm.nih.gov/articles/PMC4230661/]
- 34. Data Measurement, Instruments and Sampling - PMC [https://pmc.ncbi.nlm.nih.gov/articles/PMC12056457/]
- 35. Mixed methods instrument validation: Evaluation procedures ... [https://bmchealthservres.biomedcentral.com/articles/10.1186/s12913-023-09040-3]
- 36. The validation of research instruments is a crucial process ... [https://www.linkedin.com/pulse/validation-research-instruments-crucial-process-data-jeisil-dk1dc]
- 37. Creating and Validating an Instrument [https://www.statisticssolutions.com/creating-and-validating-an-instrument/]
- 38. Training Management System - Ultimate Guide [2025] [https://www.arlo.co/training-management-system]
- 39. A survey assessing the impact of symptoms related to ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12398178/]
- 40. 25 Best Workflow Management Tools In 2025 [https://www.cflowapps.com/best-workflow-management-tools/]
- 41. Text has enhanced contrast | ACT Rule | WAI [https://www.w3.org/WAI/standards-guidelines/act/rules/09o5cg/]
- 42. Text has enhanced contrast - Rules - Siteimprove [https://alfa.siteimprove.com/rules/sia-r66]
- 43. Key considerations to reduce or address respondent ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC9556436/]
- 44. Strategies to Minimize Burden in Clinical Trials with COAs ... [https://www.castoredc.com/blog/strategies-minimize-participant-healthcare-provider-burden-clinical-trials/]
- 45. Overcoming Study-Patient Burdens in Medical Research [https://sanguinebio.com/overcoming-study-patient-burdens-in-medical-research/?srsltid=AfmBOooSxDZlbK80JPDlcqojS-rpGPfNq3IlKOR35_qUaWwE7jF8AGF3]
- 46. Recommendations to address respondent burden ... [https://www.nature.com/articles/s41591-024-02827-9]
- 47. Strategies for longitudinal recruitment and retention with ... [https://www.sciencedirect.com/science/article/abs/pii/S019074091930903X]
- 48. Strategies for participant retention in long term clinical trials [https://pmc.ncbi.nlm.nih.gov/articles/PMC10003583/]
- 49. The Crucial Role of Medication Adherence in Clinical Trials [https://adheretech.com/the-crucial-role-of-medication-adherence-in-clinical-trials/]
- 50. Retention strategies in longitudinal cohort studies [https://bmcmedresmethodol.biomedcentral.com/articles/10.1186/s12874-018-0586-7]
- 51. Top 15 Mobile Data Collection Tools You Need to Try in 2025 [https://www.zonkafeedback.com/blog/mobile-data-collection-tools]
- 52. How to troubleshoot - real failures in ARM... time data capture [https://www.omi.me/blogs/firmware-guides/how-to-troubleshoot-real-time-data-capture-failures-in-arm-ds-5-debugger]
- 53. Prediction premenstrual syndrome (PMS) with anxiety, and ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12359940/]
- 54. The 5 best data collection tools [https://zapier.com/blog/best-data-collection-apps/]
- 55. Top 19 Mobile App Analytics Tools 2025 [Updated] [https://uxcam.com/blog/top-10-analytics-tool-for-mobile-in-2018/]
- 56. The Importance of Data Integrity in the Life Sciences Sector [https://pharmallies.com/key-faqs-on-ensuring-data-integrity-in-the-life-sciences-industry/]
- 57. Common Data Integrity Issues (and How to Overcome Them) [https://www.dataversity.net/articles/common-data-integrity-issues-and-how-to-overcome-them/]
- 58. Data Integrity in Clinical Research [https://ccrps.org/clinical-research-blog/data-integrity-in-clinical-research]
- 59. Premenstrual dysphoric disorder as a potential ... [https://www.frontiersin.org/journals/endocrinology/articles/10.3389/fendo.2025.1580947/full]
- 60. Real-world application of large language models for ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12630577/]
- 61. Guidelines for Research Data Integrity (GRDI) - PMC [https://pmc.ncbi.nlm.nih.gov/articles/PMC11739391/]
- 62. Premenstrual Dysphoric Disorder - StatPearls - NCBI Bookshelf [https://www.ncbi.nlm.nih.gov/books/NBK532307/]
- 63. PMS & PMDD - MGH Center for Women's ... [https://womensmentalhealth.org/specialty-clinics/pms-and-pmdd/]
- 64. Premenstrual Dysphoric Disorder (PMDD) [https://www.hopkinsmedicine.org/health/conditions-and-diseases/premenstrual-dysphoric-disorder-pmdd]
- 65. Evidence-based treatment of Premenstrual Dysphoric ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC7716347/]
- 66. Premenstrual dysphoric disorder as a potential predisposing ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12558772/]
- 67. PMS and PMDD: Overview and Current Treatment ... [https://www.uspharmacist.com/article/pms-and-pmdd-overview-and-current-treatment-approaches]
- 68. Emotion Generation and Regulation in Premenstrual ... [https://www.sciencedirect.com/science/article/pii/S0006322325012429]
- 69. Method validation studies and an inter-laboratory cross ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC6041428/]
- 70. ICH M10 Guidelines for Bioanalysts [https://labtesting.wuxiapptec.com/2025/07/30/ich-m10-what-the-finalized-guideline-means-for-bioanalytical-scientists/]
- 71. Comparison between retrospective premenstrual ... [https://gremjournal.com/journal/01-2021/comparison-between-retrospective-premenstrual-symptoms-and-prospective-late-luteal-symptoms-among-college-students/]
- 72. Cognitive function evaluation in premenstrual syndrome ... [https://www.sciencedirect.com/science/article/pii/S266649762200008X]
- 73. Comparability assessment [https://www.iais.org/activities-topics/standard-setting/comparability-assessment/]
- 74. Troubleshooting Guide: ELISA [https://www.rndsystems.com/resources/troubleshooting-guide-elisa-development]
- 75. Understanding WCAG 2 Contrast and Color Requirements [https://webaim.org/articles/contrast/]
- 76. Retrospective Study: Definition & Examples [https://statisticsbyjim.com/basics/retrospective-study/]
- 77. Premenstrual and Menstrual Symptoms Rating Scales [https://www.physio-pedia.com/Premenstrual_and_Menstrual_Symptoms_Rating_Scales]
- 78. Methods for studying the menstrual cycle in adolescents [https://pmc.ncbi.nlm.nih.gov/articles/PMC10843271/]
- 79. The Use of Biomarkers in Precision Health Symptom ... [https://www.sciencedirect.com/science/article/pii/S0749208125000798]
- 80. The Complete Guide to Biomarker Testing [https://superpower.com/library/guide-to-biomarker-testing?srsltid=AfmBOop3YIAKvmgkXtE9n5kuV_wphTPDIh0DCcFYxuXJXt6cMUEAAP7r]
- 81. Using biomarkers to inform diagnosis, guide treatments and ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC4043396/]
- 82. A study paradigm integrating prospective epidemiologic ... [https://www.nature.com/articles/s41467-018-05624-4]
- 83. Adding value to real-world data: the role of biomarkers - PMC [https://pmc.ncbi.nlm.nih.gov/articles/PMC6909909/]
- 84. False Positive Pregnancy Tests, Explained - Clearblue [https://www.clearblue.com/pregnancy-tests/false-positive-results]
- 85. Temporal distribution shift in real-world pharmaceutical data [https://www.sciencedirect.com/science/article/pii/S266731852500008X]
- 86. Addressing patient heterogeneity in disease predictive ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC8751174/]
- 87. Analysis of temporal survival trends: considerations and ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11847396/]
- 88. Analysis of temporal survival trends: considerations and best ... [https://bmcmedresmethodol.biomedcentral.com/articles/10.1186/s12874-025-02505-5]